How is synthetic data generated?
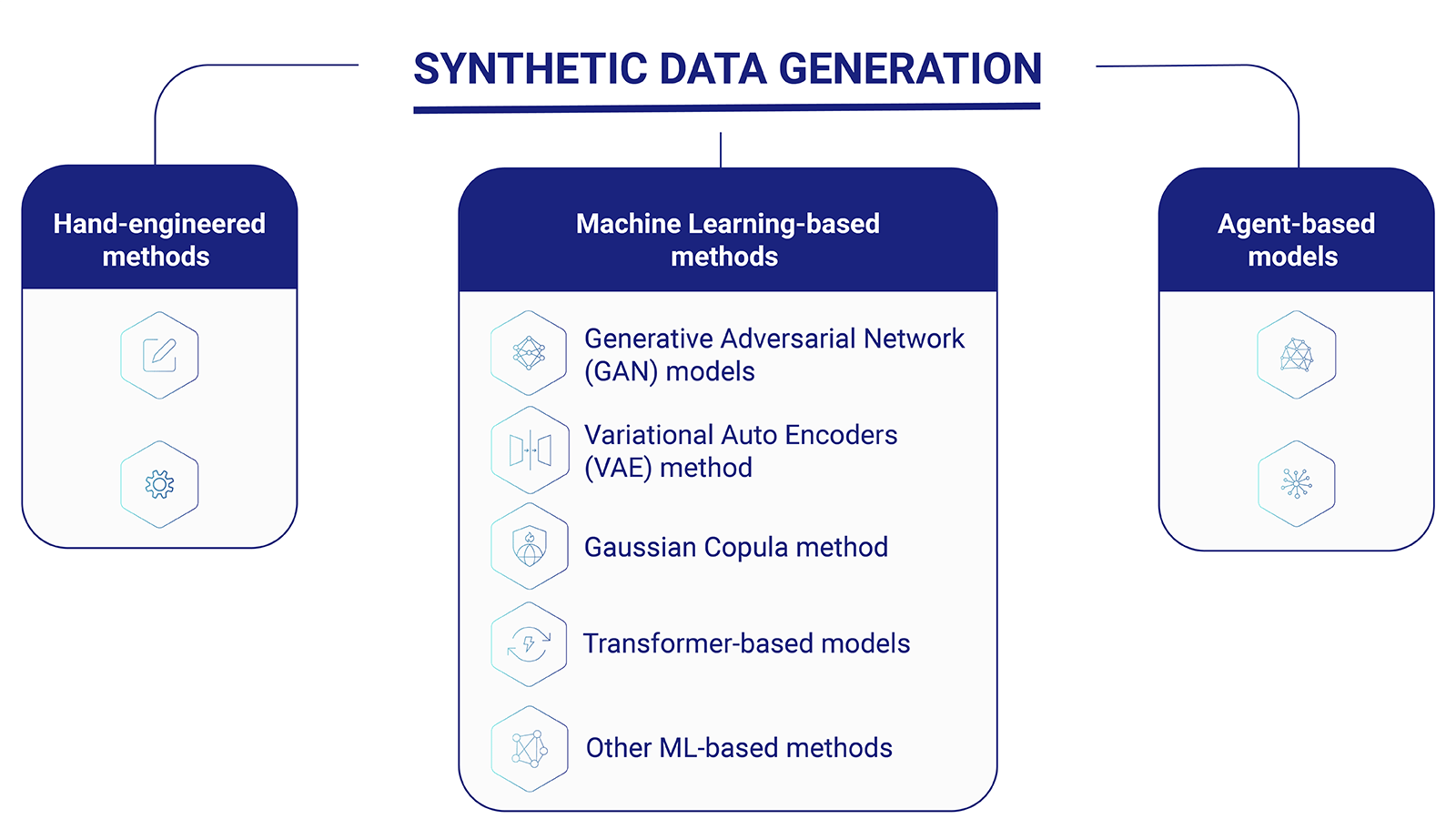
Synthetic data is created programmatically, with various techniques falling into three main branches: machine learning-based models, agent-based models, and hand-engineered methods.
There are several different methods for creating synthetic data with ML-based models, depending on the use case and data requirements. Some of the most common ones include:
-
Generative adversarial network (GAN) models – Synthetic data generation happens using a two-part neural network system, where one part works to generate new synthetic data and the other works to evaluate and classify the quality of that data. This approach is widely used for generating synthetic time series, images, and text data.
-
VAE (Variational Auto Encoders) - This approach uses a generative adversarial network system with an additional encoder to generate synthetic data that is highly realistic and similar in structure, features, and characteristics to real data.
-
Gaussian Copula (Statistics based) - This method uses a statistical methodology to generate realistic synthetic data with desired properties, such as being normally distributed. It is commonly used for data that has a discrete distribution, such as the probability of encountering certain events.
-
Transformer-based models - These models, such as OpenAI's GPT (Generative Pre-trained Transformer), excel at capturing intricate patterns and dependencies within the data. By training on large datasets, they learn the underlying structure and generate synthetic data that closely resembles the original distribution. Transformer-based models are extensively applied in natural language processing tasks, but they have also found applications in computer vision, speech recognition, image synthesis, music generation, and video sequence generation.
Additionally, agent-based models simulate the behavior and interactions of individual agents (entities) in a system to generate synthetic data. These models are particularly useful for scenarios where the behavior of individual entities contributes to the overall pattern observed in the data. They can include:
-
Traffic Simulation - In transportation studies, agent-based models can be used to simulate the movement of individual vehicles in a city. Each vehicle is treated as an agent with specific rules for acceleration, deceleration, and lane changes. This approach can generate synthetic traffic flow data, which is useful for testing and optimizing transportation systems.
-
Epidemiological Models - Agent-based models are frequently used in epidemiology to simulate the spread of infectious diseases. Each person in the model represents an agent, and their interactions (e.g., contact rates, infection probabilities) with other agents determine the disease transmission. Synthetic data generated through such models can help in studying the impact of interventions and predicting disease outbreaks.
-
Market Simulation - In finance, agent-based models can simulate the behavior of individual traders in a financial market. Each trader agent may have different strategies and risk preferences. By simulating their interactions and trading decisions, the model can generate synthetic financial market data, which can be used for testing trading algorithms and risk management strategies.
Hand-engineered methods involve designing rules and algorithms to generate synthetic data. These methods are often used when the underlying data distribution is well-understood and can be represented using specific mathematical or statistical models.
-
Rule-based data generation - In this approach, synthetic data is created based on a set of predefined rules and conditions. For example, let's say you have a dataset of sales transactions with customer information. To generate synthetic data, you could define rules like "create new transactions for each customer with random purchase amounts and dates, ensuring the purchase dates are within a reasonable range from the original data.”
-
Parametric models - Parametric models are mathematical representations of the data distribution, and synthetic data is generated by sampling from these models.
-
Random Sampling - In this simple approach, synthetic data is generated by randomly sampling from the existing data. For example, if you have a dataset of people's ages, you can generate synthetic data by randomly selecting ages from the original dataset.
-
Linear Interpolation - Suppose you have a dataset with time-series data points. You can use linear interpolation to generate synthetic data points between existing ones, creating a smoother time-series representation.
Each method has its benefits, and some algorithms can be combined to optimize synthetic data generation for specific use cases. Ultimately, the best approach will depend on your organization's needs and data requirements.
How to determine synthetic data quality?
One of the main challenges in using synthetic data is determining its quality and accuracy. Many factors affect the quality of synthetic data, including the dataset size, the number of variables included, and how well it mimics real, actual data.
Some key considerations when evaluating the quality of synthetic data include the randomness of the sample, how well it captures the statistical distribution of real data, and whether it includes missing or erroneous values. Other factors include whether the dataset has been bootstrapped or trained on real data and whether it's been validated or tested by comparing it to actual values.
Generative models like Generative Adversarial Networks (GANS) or Variational Autoencoder (VAE) can be evaluated with metrics like Inception Score or FID score, which are used to compare the quality of synthetic data against real data. The aspects of synthetic data these metrics generally consider are similarity with training data and diversity within itself.
Another thing to consider when evaluating synthetic data quality is how well it protects data privacy and security. Different synthetic data techniques have different levels of risk when revealing sensitive information, and some are more vulnerable to cyberattacks than others.
Organizations should consider a few key factors when evaluating their synthetic data's privacy, security, and risk levels. These include how well it protects sensitive information if it is properly anonymized and de-identified and whether it could be reverse-engineered to reveal individual identities. They should also consider the probability of data leaks and hacks and whether their synthetic data techniques are robust enough to withstand tampering or attacks.
After an organization has taken the necessary measures to ensure its generated synthetic datasets are of high quality, it's important to evaluate the effectiveness of these measures. To do so, synthetic data is measured against three key dimensions: fidelity, utility, and privacy, as explained in more detail in the article “How to evaluate synthetic data quality.”

Ultimately, the quality of synthetic data depends on the specific use case and requirements. No single standard or metric can be used to evaluate its quality across all applications, especially considering the quality of certain synthetic data, such as synthetic images, is very subjective.

Democratizing Data Access with Synthetic Data Whitepaper
Find out how synthetic data empowers your organization to tackle data-related challenges, improve decision-making, and maintain compliance with data protection regulations.
Synthetic data use cases within specific industries
Many industries already leverage the potential of synthetic data. For example, financial institutions use synthetic data to generate reliable market data for algorithmic trading and risk analysis, while healthcare providers use it to analyze patient data without compromising sensitive patient information.
Synthetic data for insurance companies
Insurance companies struggle to find and access high-quality datasets for predictive modeling, pricing analysis, and risk assessment. Synthetic data helps insurance providers simulate real-world datasets and improve their predictive capabilities, allowing them to make more accurate risk assessments and price insurance policies more effectively.
In addition to improving their predictive capabilities, synthetic data helps insurance companies optimize internal workflows, evaluate new products and services, and reduce data collection and management costs. By providing a realistic dataset that mimics real-world data, synthetic datasets reduce the need to collect and store large volumes of real data while also improving the efficiency and accuracy of their models.
Use cases of synthetic data in the insurance sphere include the following:
Reinventing risk assessment
Risk assessment lies at the heart of the insurance industry, driving critical decisions that determine premiums, coverage, and overall business strategies. However, traditional risk assessment methods often fall short of capturing the complexities of the modern world.
Unlike conventional data collection, limited by historical data or specific demographics, synthetic data is tailored to include various risk factors and demographic variables. This enables insurers to make more accurate risk predictions and better understand potential outcomes.
Another significant advantage of synthetic data in risk assessment is its ability to account for extreme or rare events. In the real world, certain events may occur infrequently but have a significant impact when they do. With synthetic data, insurers simulate these rare occurrences and assess their potential consequences, allowing them to develop more robust risk models.
Reshaping claims processing
Claims processing is another critical function for insurance companies, as it directly impacts customer satisfaction and operational efficiency. Traditionally, claims processing has been a labor-intensive and time-consuming process, often prone to errors and delays.
One of the key benefits of using synthetic data in claims processing is the ability to create realistic and diverse datasets that represent various types of claims. It allows insurers to simulate different scenarios, from routine claims to complex and rare events. Additionally, it accelerates the claims processing timeline, leading to faster and more efficient service for policyholders.
Detecting fraud deception
If anything results in substantial financial losses and damage to an insurer's reputation, it is fraud. Detecting and preventing fraud requires advanced techniques and robust algorithms, exactly what synthetic data provides.
It offers a unique advantage in fraud detection by allowing insurers to create realistic and diverse fraud scenarios. Fraudsters continuously evolve their tactics to evade detection, making it challenging for traditional fraud detection methods to keep up.
Another crucial advantage of using synthetic data for fraud detection goes back again to its ability to safeguard customer privacy. Fraud detection algorithms require access to sensitive data, making privacy protection a significant concern. Synthetic data provides a privacy-compliant solution by generating data containing no customer information, ensuring individual privacy is upheld throughout the fraud detection process.
Software testing with synthetic data
Using personal data in development and testing environments has become a significant concern, especially in light of stringent privacy regulations like GDPR, CPRA, and ISO 27001, including its newest version from 2022. In the past, developers often used real customer data to test new features and identify bugs. However, with more stringent privacy regulations, this leads to significant privacy risks.
Another issue worth mentioning when discussing software testing is the challenges associated with hiring and retaining technical talent. According to a 2023 Gartner survey of software engineering leaders, talent hiring, development, and retention are the top challenges they currently face.
This emphasizes the importance of improving test data management (TDM) practices to alleviate the burden on product teams and enhance software testing processes. Synthetic data offers a new approach to TDM, allowing insurance companies to avoid the challenges of utilizing production data for testing purposes.
Embracing inclusivity: Combating bias
As data-driven decision-making becomes increasingly prevalent, the insurance industry is less of a stranger to discrimination. Exclusionary underwriting practices and bias in data-driven applications can lead to unfavorable outcomes for specific groups.
Bias in AI algorithms has far-reaching implications for insurers and their customers, leading to unfair treatment and higher premiums for certain customer groups and inadequate coverage for others. Unlike real-world data, synthetic data is artificially generated with precision and tailored to include diverse demographics, ensuring fair and accurate representations of various customer groups.
Synthetic data in banking and finance companies
Banks and financial institutions face various challenges using real-world data in their operations. Some of the biggest issues they face include the high cost of data collection and management, the limited availability of high-quality datasets, and regulatory risks around data privacy.
If we add growing cybersecurity concerns, money laundering, and restricted access to transaction data to the mix, banks and financial institutions face significant challenges with using real-world data in their operations.
However, synthetic data is changing the game for financial institutions by offering a solution to overcome usage limitations, privacy concerns, and security risks. Synthetic data provides realistic datasets that allow organizations to train machine learning models, evaluate new products and services, and improve operations without exposing sensitive customer information.
The use cases of synthetic data are extensive across various finance domains, including:

Anti-money laundering (AML)
Money laundering is a significant concern for financial institutions, and AML models play a critical role in detecting suspicious activity. Synthetic data generates large sets of synthetic transactions, enabling organizations to train and test their AML models more accurately. It helps identify potential accounts, transactions, payments, and withdrawals or purchases, allowing institutions to hone their AML models and stay ahead of new criminal tactics.
Fraud detection and risk management
By generating synthetic data that mimics real-world fraud patterns, institutions improve their fraud detection models and reduce the number of false positives. Synthetic data helps banks simulate different risk scenarios to fine-tune their risk management strategies and ensure they are operating at optimal levels.
Data bias reduction
Data bias is one of the challenges of using real-world data, leading to models that perpetuate this bias. Synthetic data helps reduce the risk of data being used to perpetuate prejudices by creating datasets more representative of the entire population, including underrepresented groups.
Credit scoring and loan origination
Synthetic data generates digital twins of customers and simulates their credit scores, enabling lenders to make more accurate loan origination decisions. By simulating a broad range of scenarios and borrower characteristics and behaviors, institutions will better understand the creditworthiness of their clients, leading to more accurate credit decisions and better risk management.
Portfolio optimization
Portfolio optimization is the process of selecting the optimal mix of investments to achieve a specific financial objective. Synthetic data helps institutions generate vast amounts of data on different investment scenarios and evaluate the performance of various portfolios. This helps them identify the most profitable and efficient portfolios, leading to better returns for their clients.
Stress testing and scenario analysis
Synthetic financial data is especially useful for stress testing and scenario analysis. This involves creating hypothetical scenarios and simulating how a portfolio or financial instrument would perform under those conditions. Synthetic data enables institutions to generate a diverse range of scenarios that are difficult or impossible to obtain from real-world data, allowing them to test the robustness of their models and prepare for a range of potential market conditions.
Synthetic data in healthcare and pharma
To improve research and development workflows, healthcare organizations rely on large-scale datasets to create personalized medicine, improve drug discovery capabilities, and perform predictive analytics. However, due to privacy regulations and data ownership concerns, researchers struggle to access accurate datasets for running clinical trials, developing new medical treatments, and improving patient outcomes.
Synthetic data offers a compelling solution to these challenges, allowing healthcare and pharma companies to create realistic datasets to train and evaluate machine learning models without compromising the confidentiality of patient information. It provides a fast and cost-effective way to model real-world data and optimize workflows while minimizing risk and maintaining compliance with privacy regulations.
In the healthcare and pharma industries, various data types are generated using synthetic data generation techniques. Image data, such as medical imaging scans, has been at the forefront of medical advancements, enabling more accurate diagnoses and AI-powered surgical guidance systems.
However, the potential of artificial intelligence extends beyond image analysis. While they have been essential for medical advancements, other data types, such as tabular healthcare data (electronic health records, lab results, etc.), also hold great value for AI applications in healthcare.
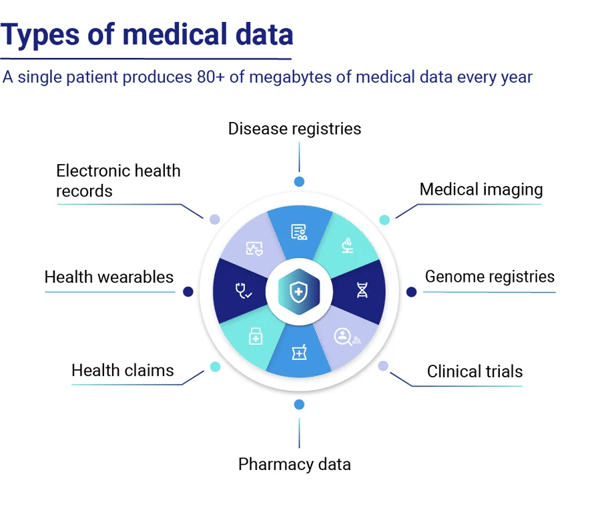
Source: Huesch, D., and Mosher, T. J. (2017). Using It or Losing It? The Case for Data Scientists Inside Health Care. NeJM Catalyst. Available online at: https://catalyst.nejm.org/case-data-scientists-inside-health-care/

Unlocking New Possibilities in Banking and Finance with Synthetic Data: The Story of SIX - Case Study
Learn how SIX AG leveraged Syntheticus to generate accurate and diverse data for improved decision-making and reduced risk in the banking and finance industry.