Preserving privacy, unleashing data: Exploring the power of privacy-enhancing technologies (PETs)

Privacy-enhancing technologies (PETs) are a collection of digital technologies and approaches that allow for the collection, processing, analysis, and sharing of information while safeguarding the privacy of personal data. They enable a relatively high level of utility from data while minimizing the need for extensive data collection and processing.
In fact, PETs have the potential to unlock a staggering amount of value in underutilized data. According to estimates, PETs are projected to unleash between $1.1 trillion and $2.9 trillion of value, as highlighted in a report by Lunar Ventures. These technologies are not only crucial for protecting privacy but also offer substantial economic benefits by tapping into the untapped potential of data.
PETs have become increasingly important in today's data-driven era as individuals recognize the value and potential risks associated with their personal data. They offer a promising way to maintain data privacy in an age where organizations and governments increasingly utilize various digital technologies, from artificial intelligence (AI) to machine learning, for advanced analytics and decision-making.
By 2030, data marketplaces enabled by PETs, in which individuals, corporates, machines, and governments trade data securely, are poised to become the second-largest ICT market after the Cloud, as stated by Lunar Ventures.
In this article, we will delve into the world of PETs and discover their role in balancing privacy and data utilization. We will explore the different types of PETs, the significance of the US-UK Atlantic Declaration, and the potential of synthetic data as a powerful tool for enhancing privacy and unlocking data value. Finally, we will introduce the tree approach for selecting the right PET.
Understanding Privacy-Enhancing Technologies (PETs)
As we briefly mentioned in the introduction, PETs are digital technologies and approaches, instrumental in preserving privacy while enabling the effective utilization of data. Their significance lies in their ability to address the inherent tension between privacy and data utilization, which has often been viewed as a zero-sum game. PETs offer a way to strike a balance, allowing organizations to derive value from data while safeguarding individuals' privacy rights.
The Information Commissioner's Office (ICO), the regulatory body in the United Kingdom responsible for overseeing data protection and privacy, plays a vital role in providing guidance to organizations interested in implementing PETs to ensure compliance with data protection laws. On 19 June 2023, the ICO published guidance specifically on privacy-enhancing technologies (PETs) (the Guidance), emphasizing the importance of utilizing PETs to share personal data safely, securely, and anonymously.
The Guidance clarifies there is no specific legal definition of PETs within data protection law, however the ICO’s view is that PETs are technologies that embody fundamental data protection principles by minimizing personal data use, maximizing information security, and/or empowering individuals. The ICO's PETs guidance focuses on PETs that organizations can utilize, providing descriptions of common types of PETs that offer privacy-enhancing functionality, security-enhancing functionality, and empowerment functionality.
Additionally, the OECD report on “Inventory of Privacy-Enhancing Technologies” provides a broad definition of PETs. It states:
“Privacy-enhancing technologies (PETs) commonly refer to a wide range of technologies that help protect personal privacy. Ranging from tools that provide anonymity to those that allow a user to choose if, when and under what circumstances personal information is disclosed, the use of privacy-enhancing technologies helps users make informed choices about privacy protection.
PETs can empower users and consumers seeking to control the disclosure, use, and distribution of personal information on line. PETs can also aid businesses and organisations in enforcing their own privacy policies and practices. In an era of consumer concerns about online privacy, PETs are crucial tools in managing the flow of personal information on global public networks”.
The European Union Agency for Cybersecurity (ENISA) refers to PETs as “software and hardware solutions, i.e. systems encompassing technical processes, methods, or knowledge to achieve specific privacy or data protection functionality or to protect against risks to privacy of an individual or a group of natural persons”.
While PETs are not new, recent connectivity and computational capacity advancements have brought a fundamental shift in how data is processed and shared. These developments hold immense potential to promote the ongoing practice of privacy by design and foster trust in data sharing and re-use.
As the importance of PETs continues to grow, an increasing number of policymakers and privacy enforcement authorities are considering their incorporation into domestic privacy and data protection frameworks. However, the highly technical and rapidly evolving nature of these technologies often poses challenges for organizations when it comes to implementation, as well as for policymakers and legal frameworks aiming to address data-related issues.
PETs categories and applications
So, what do PETs look like in practice? A wide range of PETs have been developed over the years, with more emerging constantly.
Most PETs fall into one of five categories: homomorphic encryption, secure multi-party computation, federated learning, differential privacy, and AI-generated synthetic data. Each has its unique advantages and is utilized for various purposes, from improving privacy to unlocking the potential of data.
Let’s look at each of them in more detail.
1. Homomorphic encryption
Homomorphic encryption is a type of encryption that allows computations to be performed on data without decrypting it - while still in an encrypted state. This means that the data will remain secure and only be accessed by those with permission.
Homomorphic encryption is used for various applications, from data storage and sharing to cloud computing and analytics. It is a valuable tool for organizations with large datasets that need to be securely managed and shared while allowing the data to be used for analytics and other purposes.
2. Secure Multi-Party Computation (SMPC)
SMPC is a type of PET that allows multiple parties to jointly compute a function while keeping their data secure from one another. It is an especially useful tool for organizations that must collaborate and share data with multiple stakeholders while preserving data privacy.
Secure multi-party computation finds applications in scenarios such as medical research, where multiple entities need to collaborate without exposing sensitive data. It is also used in areas such as finance and banking, where it helps preserve the confidentiality of data while allowing for joint analysis and decision-making.
3. Federated learning
Federated learning is a type of machine learning that enables the training of machine learning models across multiple decentralized devices without transferring the raw data to a central server.
Each device trains the model using its local data, and only aggregated updates get shared with the central server. This helps preserve data privacy as the raw data remains on the devices and is never shared.
Federated learning is useful for scenarios involving connected devices and distributed data, such as IoT or mobile applications. It is used to build personalized models that are more accurate than those based on centralized data.
4. Differential privacy
Differential privacy is a type of PET that ensures privacy by adding noise or randomness to individual data points, making it challenging to identify specific individuals while still providing valuable insights at the aggregate level.
This technique allows organizations to protect individuals’ privacy while conducting data analysis on large datasets and leveraging the insights gained to make decisions. Differential privacy is often used in areas such as healthcare, where it provides valuable insights while safeguarding patient privacy.
5. Trusted Execution Environment
Trusted Execution Environment (TEE) is another important aspect of PETs. It provides a secure and isolated processing environment within a computer system where sensitive operations are executed away from a computer’s main processor and memory, ensuring the confidentiality and integrity of data and code
By utilizing TEE, organizations can protect critical processes and computations, such as cryptographic operations, key management, and secure data processing. CYSEC, the company Syntheticus partners with, specializes in providing trusted execution environments for containers and helps them to secure and deploy sensitive data on distributed architecture from Data center to the Cloud to the Edge.
6. AI-Generated synthetic data
The last type of PET we will discuss is AI-generated synthetic data. This approach uses advanced AI algorithms to generate synthetic data with the same statistical properties and correlations as real data but without including personally identifiable information.
Synthetic data has gained increasing importance within the PET landscape, offering a privacy-preserving alternative for data analysis and model training without sacrificing data accuracy.
In addition to protecting privacy, synthetic data is used to train and test machine learning models in a secure environment, as well as to enable data sharing between stakeholders. By using it, organizations reduce the need to access sensitive personal information while benefiting from realistic and representative datasets.
Leveraging PETs for privacy and data utilization
PETs bring tremendous value to organizations through their ability to both protect individuals' privacy and enable data utilization. They facilitate responsible AI development, machine learning, and advanced analytics by ensuring compliance with privacy regulations and ethical data practices.
Many organizations are already embracing PETs to strike the right balance between privacy and data utilization. For instance, companies in the retail sector utilize PETs to analyze customer purchasing behavior without accessing personal identifiers. This approach enables targeted marketing campaigns while preserving individual privacy.
In healthcare, PETs enable secure collaboration on patient data for research purposes while protecting sensitive medical information. In the financial sector, PETs help detect fraud and ensure the confidentiality of customer data during data analysis. These are just a few examples of how PETs are leveraged to maintain privacy and enhance data utilization across various industries.
PETs are often used together, combining different techniques to maximize privacy protection and data utilization. For instance, by partnering with CYSEC, Syntheticus provides a comprehensive solution that combines synthetic data generation and differential privacy techniques with Trusted Execution Environment. This powerful combination ensures not only the accuracy and privacy preservation of the data but also the secure execution of critical operations within a trusted environment.
That said, the complexities associated with implementing PETs can sometimes seem intimidating, especially in the early stages. Some organizations may not have the resources to develop or implement their own solutions, while others may be hindered by legacy systems and processes that make it difficult to adopt modern PETs cost-effectively. Often, the best approach for organizations looking to leverage PETs is to work with a trusted partner to provide them with the necessary tools and expertise.
The significance of the US-UK Atlantic Declaration
The Atlantic Declaration, announced by the U.K. Prime Minister Rishi Sunak and U.S. President Joe Biden this June, marks a significant milestone in developing a comprehensive U.S.-U.K. data and artificial intelligence partnership. The declaration addresses the challenges associated with data sharing across borders while complying with privacy laws, which has been a complex issue for organizations globally.
Over the years, there has been regulatory instability and uncertainty regarding transferring personal data to the U.S., starting with the Snowden disclosures and culminating in the EU General Data Protection Regulation (GDPR) enforcement against Meta. However, with new and improved U.S. laws and practices that enhance privacy safeguards in the national security and law enforcement context, both the U.K. and the European Union are on track to finalize regulatory arrangements endorsing U.S. standards.
The U.K. government has prioritized establishing a data bridge with the U.S. since leaving the EU. This involves negotiating a successor to the Privacy Shield framework directly with the U.S. Before finalizing the arrangement, tasks must be completed on both sides. The U.K. government needs to seek the advisory opinion of the Information Commissioner's Office and introduce legislation to the U.K. Parliament. The U.S. needs to designate the U.K. as a "Qualifying State," acknowledging its comparable privacy safeguards in the context of national security.
Regarding AI governance, there is a global push to establish guidelines and frameworks to ensure AI's safe and responsible implementation. The Atlantic Declaration acknowledges the U.K.'s "comprehensive and balanced" approach to AI risks and opportunities, with the U.K. set to host the first international governmental summit on AI safety. This multilateral effort aligns with initiatives undertaken by various organizations and alliances, including the G7, OECD, UNESCO, ISO, African Union, and Council of Europe.
Privacy-enhancing technologies are recognized as a paradigm shift in addressing the tension between privacy and data utilization. PETs enable organizations to unlock the value of data while preserving privacy rights and are considered a crucial component of AI governance. The Atlantic Declaration highlights a new collaboration on PETs between the U.S. and the U.K., as evidenced by the announcement of the inaugural winners of the UK-U.S. PETs prize challenge.This collaboration aims to incentivize the development of PETs and promote their adoption.
In conclusion, the Atlantic Declaration signifies the joint efforts of the U.S. and the U.K. to bridge the policy divide on data, AI, and governance. The declaration aims to promote data transfers and AI governance that align with privacy safeguards and global standards by fostering a more scalable and multisided international approach.
The Privacy Enhancing Technology Research Act
In a significant move to support research and promote responsible data use, the United States Congress recently introduced the Privacy Enhancing Technology Research Act, also known as H.R.4755. This bill underscores the growing importance of PETs in today's data-driven landscape and aims to accelerate the development, deployment, and adoption of privacy-enhancing technologies across various sectors.
The Privacy Enhancing Technology Research Act outlines key objectives and areas of focus for the National Science Foundation (NSF) and other relevant federal agencies in supporting research on PETs. The bill emphasizes the need to address individuals' privacy risks in data sets while maintaining fairness, accuracy, and efficiency. It also encourages research on algorithms and mathematical tools that protect individual privacy during data collection, storage, sharing, analysis, and aggregation.
Furthermore, the bill aims to foster multidisciplinary socio-technical research to better understand privacy preferences, requirements, and human behavior. It advocates for the development of freely available privacy-enhancing technology software libraries, platforms, and applications, making PETs more accessible to various stakeholders.
A key aspect of the Privacy Enhancing Technology Research Act is its emphasis on promoting the responsible use of PETs in data collection, sharing, and analytics performed by both the public and private sectors. By integrating privacy-enhancing technologies into the Computer and Network Security Program and coordinating with the National Institute of Standards and Technology (NIST) and other stakeholders, the bill aims to establish voluntary, consensus-based technical standards, guidelines, and methodologies that enhance privacy protections.
As this bill progresses through the legislative process, it marks a significant milestone in the efforts to strike a balance between data utilization and privacy protection, setting the stage for greater innovation and responsible data practices in the years to come.
Synthetic data as a Privacy-Enhancing Technology
Synthetic data as a privacy-enhancing technology, offers numerous use cases across various industries. Its ability to provide privacy-preserving alternatives to real data allows organizations to leverage its benefits while protecting individual privacy.
Here are some prominent use cases of synthetic data:
Machine learning model training |
Synthetic data is used to train machine learning models without exposing sensitive or personally identifiable information. By generating synthetic datasets that mimic the statistical properties of real data, organizations develop accurate and effective models while ensuring privacy. |
Data sharing and collaboration |
Synthetic data is used to train machine learning models without exposing sensitive or personally identifiable information. By generating synthetic datasets that mimic the statistical properties of real data, organizations develop accurate and effective models while ensuring privacy. |
Testing and validation |
In software development and testing, synthetic data serves as a valuable substitute for real data when testing and debugging new features, optimizing performance, and improving user experience. It allows developers to understand system functionality, logic, and flow before actual data becomes available. This accelerates development workflows and reduces time-to-market. |
Compliance and auditing |
Synthetic data assists organizations in meeting regulatory requirements and undergoing privacy audits. It allows them to demonstrate compliance with privacy regulations by generating synthetic datasets that adhere to privacy guidelines without revealing sensitive information. |
Benchmarking and comparative analysis |
Enabling organizations to compare and benchmark datasets is yet another use of synthetic data. By generating precise artificial datasets that replicate the statistics and analysis performed on real-world data, organizations can make meaningful comparisons, benchmark performance, and improve decision-making. |
Training and education |
In software development and testing, synthetic data serves as a valuable substitute for real data when testing and debugging new features, optimizing performance, and improving user experience. It allows developers to understand system functionality, logic, and flow before actual data becomes available. This accelerates development workflows and reduces time-to-market. |
Real-world scenario simulation |
Synthetic data simulates real-world scenarios for various purposes, such as urban planning, transportation optimization, or epidemiological studies. It allows organizations to generate synthetic datasets representing population behavior, movement patterns, or disease spread without infringing individual privacy. |
Market research and customer analysis |
By generating synthetic datasets that reflect customer trends, market research, and consumer preferences, organizations gain insights into customer behavior patterns without sacrificing privacy. The use of synthetic data allows them to better understand customer sentiment and gain insight into marketing strategies. |
It is important to note that while synthetic data provides a viable privacy-enhancing solution, it is not a silver bullet. Organizations must remain vigilant and take appropriate measures to protect sensitive data while maximizing the value of synthetic data.
In summary, synthetic data has immense potential to bridge the gap between privacy and data utilization in a world where data and AI are rapidly advancing. It is a crucial part of the global effort to establish privacy safeguards, promote data transfers, and improve AI governance.
Choosing the right PET: the tree approach
The decision of which PET to use should be driven by the data lifecycle and the industry-specific context. To make this decision, organizations can employ a helpful framework called “the tree approach”, which considers data type, purpose, and context when selecting an appropriate PET.
But before you can put the tree approach into action, you must first identify the data type and define your purpose and objectives. To do this, consider the answers to the following questions:
1. What type of data are you dealing with, and what level of privacy protection is required?
2. What is your purpose for using this data?
3. How does it fit into the context of industry-specific regulations and stakeholder requirements?
By answering these questions, you will be able to determine the type of data and its purpose while also understanding its legal constraints. This information then matches the right PET to your data and use case.
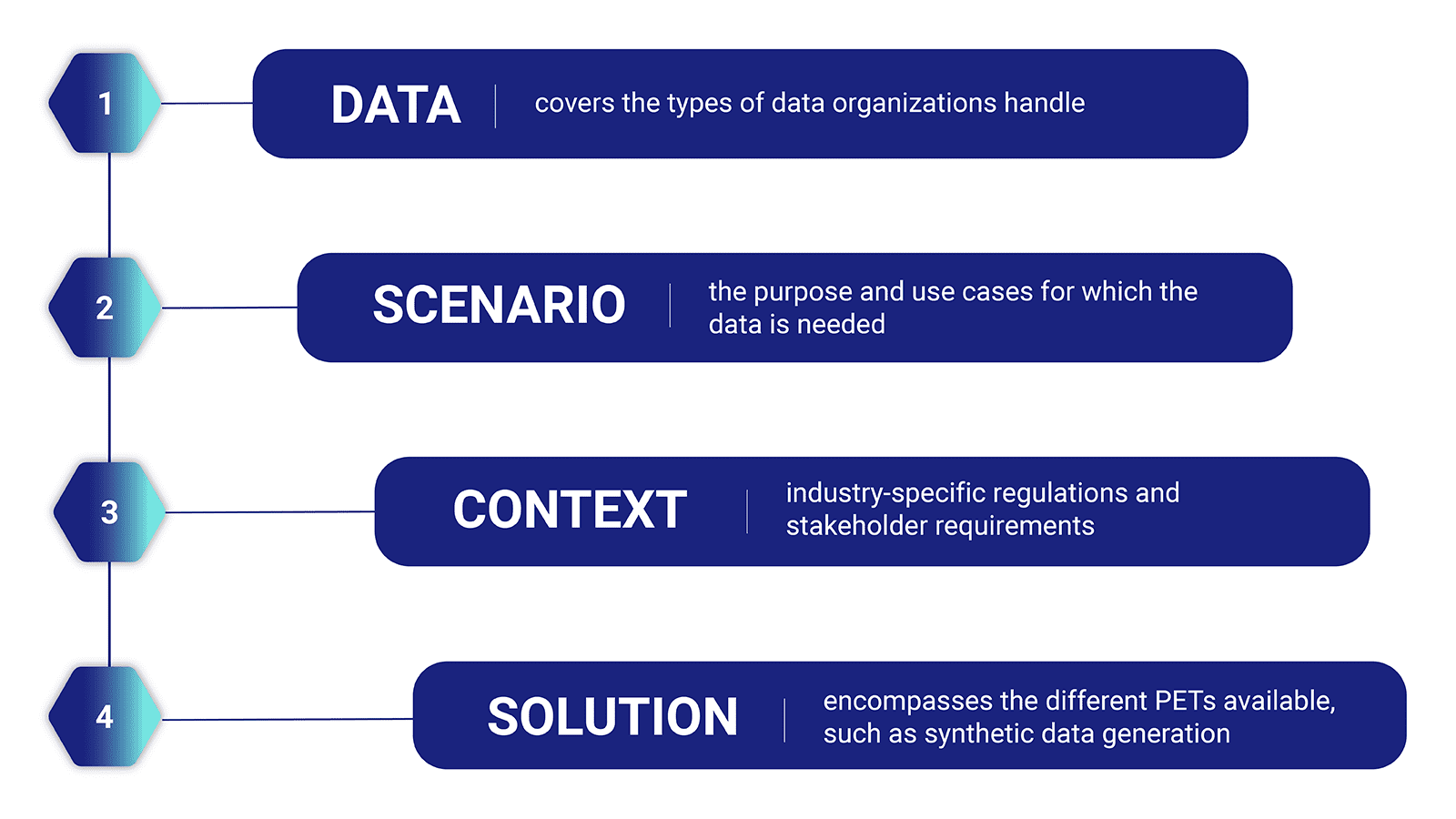
The tree approach comprises four distinct levels: data, scenario, context, and solution.
The first level — data — covers the types of data organizations handle, such as sensitive financial data, health records, or personally identifiable information, and the required level of privacy protection.
The second level — scenario — consists of the purpose and use cases for which the data is needed, such as machine learning model training or testing and debugging of new features.
Level three — context — considers industry-specific regulations and stakeholder requirements. Different jurisdictions may have varying privacy laws and regulations, and ensuring that the selected PET complies with these requirements is vital.
Finally, the fourth level — solution — encompasses the different PETs available, such as anonymization techniques or synthetic data generation, and their respective effectiveness when applied to the data, scenario, and context.
Organizations can follow the Centre for Data Ethics and Innovation PETs adoption guide to decide on the best PET for their organization, which provides a visual representation of the ‘tree approach’ that helps them identify the most suitable solution.
Additionally, Public.io has developed a tree tailored for the public administration sector. This resource provides a specialized framework for public sector organizations to evaluate and adopt PETs effectively.
Future directions and conclusion
The field of privacy-enhancing technologies is continuously evolving, driven by advancements in technology, changing privacy regulations, and the increasing need to balance privacy and data utilization. As we look to the future, several key directions and challenges will shape the landscape of PETs and their impact on privacy.
Continued innovation: PETs will evolve and improve as new technologies and techniques emerge. Researchers and developers will explore novel approaches to enhance privacy while enabling effective data utilization. This may include advancements in secure computation, privacy-preserving machine learning, and decentralized data architectures.
Regulatory landscape: Privacy regulations and data protection frameworks will play a significant role in shaping the future of PETs. As policymakers and legislators grapple with the complexities of data privacy, they must consider the potential of PETs and ensure that regulations provide a conducive environment for their development and adoption. Balancing privacy rights, data utilization, and technological advancements will be a key challenge.
Ethical considerations: PETs raise ethical questions about transparency, fairness, and accountability. As these technologies become more prevalent, it will be essential to establish ethical guidelines and frameworks that govern their use. This includes addressing issues such as algorithmic bias, informed consent, and the responsible deployment of PETs to ensure they align with societal values and promote a fair and equitable digital landscape.
Interdisciplinary collaboration: PETs require collaboration between various stakeholders, including technologists, policymakers, legal experts, and privacy advocates. Bridging the gap between technical expertise and legal frameworks is crucial to foster the effective implementation and regulation of PETs. Interdisciplinary collaborations will be essential in developing comprehensive solutions and addressing the challenges associated with PET adoption.
Education and awareness: Finally, as PETs become more prevalent, there is a need for education and awareness among individuals, organizations, and policymakers. Promoting an understanding of PETs and their benefits and addressing concerns and misconceptions will be critical for widespread adoption. Training programs, workshops, and public discourse can contribute to a more informed and privacy-conscious society.
It is worth noting that Syntheticus has been actively contributing to the PET community. The company participated in the PET Summit Europe in London in March 2023, where experts and innovators gathered to discuss the latest developments in privacy-enhancing technologies. Additionally, Syntheticus is excited to announce its participation in the upcoming PET symposium in Lausanne in July 2023, where it will share insights and collaborate with other stakeholders to drive the adoption of PETs for privacy protection and data utilization.

In conclusion, PETs offer numerous opportunities for organizations to protect privacy while maximizing data utilization. By understanding the different types of data and use cases, assessing regulatory requirements, and selecting the right PET for their organization, organizations will ensure a secure and privacy-preserving data infrastructure. Syntheticus is proud to be at the forefront of this technology, working to shape a future where privacy and data utilization go hand in hand, fostering trust, innovation, and responsible data practices.

