Beyond GDPR: how synthetic data helps companies navigate the complexities of data protection and privacy

In an increasingly digitized world, data protection and privacy have become paramount concerns for individuals and organizations alike. Safeguarding personal information and ensuring compliance with regulations such as the General Data Protection Regulation (GDPR) and the Swiss Data Protection Regulation (DPR) is essential for maintaining trust and avoiding hefty penalties. As the 5th anniversary of GDPR approaches in May 2023, it is crucial for companies to explore innovative solutions that go beyond mere compliance and address the complexities of data protection and privacy.
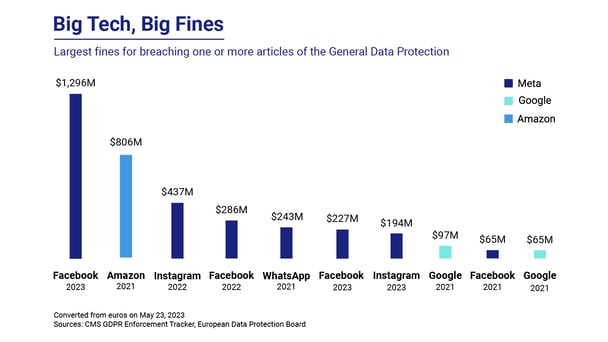
However, the road to achieving robust data privacy and compliance is not without its challenges. The impact of data protection regulations on organizations is exemplified by recent actions taken against tech giants like Google Analytics and GenAI (including OpenAI). These cases serve as reminders of the challenges involved in achieving robust data privacy and compliance. That said, the regulatory landscape becomes even more daunting when considering the staggering fines imposed on companies for GDPR breaches.
Notably, Meta (formerly known as Facebook) was recently hit with a record-breaking fine of $1.3 billion, as reported by CNN. This significant penalty sends a clear message about the severity of non-compliance with GDPR regulations. Additionally, Amazon faced a substantial fine of $888 million for its own GDPR breach. These eye-opening figures underline the financial consequences that companies may face for failing to uphold data protection and privacy standards. They also highlight the need for alternative approaches to navigate the intricate landscape of data protection while still enabling organizations to derive meaningful insights from data.
One such solution that holds promise in this context is synthetic data. Synthetic data refers to "fake", artificially generated data that mimics the characteristics and patterns of real-world data without containing any personally identifiable information (PII). By utilizing synthetic data, organizations can overcome the limitations and risks associated with using real data while still gaining valuable insights for various applications.
This blog post delves into the realm of synthetic data and its role in helping companies navigate the complexities of data protection and privacy beyond the GDPR. We will explore the definition and generation process of synthetic data, discuss its advantages over real data, and examine how it contributes to GDPR compliance and addresses privacy concerns.
Furthermore, we will explore the implications of the revised Swiss DPR and the EU-US Privacy Shield on data privacy and how synthetic data can assist companies in meeting the requirements of these regulations. Finally, we will discuss the legal considerations surrounding the use of synthetic data and offer insights into the future of synthetic data and data privacy.
Overview of GDPR, Swiss DPR, and data privacy challenges faced by companies
Before diving into the benefits of synthetic data for navigating the complexities of data protection and privacy, let us first take a look at the current regulatory landscape.
The European Union introduced the GDPR in May 2018 to protect individuals' personal data from misuse and ensure compliance with digital privacy standards.
Key Provisions of the GDPR include:
- Lawful basis for processing: Organizations must establish a legitimate basis (consent, contractual necessity, legal obligations, etc.) for processing personal data.
- Enhanced data subject rights: The GDPR grants individuals the right to access, rectify, and erase their personal data, as well as the right to object to processing and restrict its usage.
- Data breach notification: Companies must report data breaches to supervisory authorities and affected individuals within 72 hours of their discovery.
- Privacy by design and default: Privacy considerations must be incorporated into system design and operations from the outset, with privacy-friendly default settings as the standard.
- Data transfers: Transferring personal data outside the EU is subject to restrictions, requiring organizations to ensure adequate safeguards or rely on approved mechanisms.
Similarly, Switzerland, while not an EU member state, passed its new data protection framework known as the Swiss DPR or Federal Act on Data Protection (FADP) in September 2020 to meet the data privacy requirements of the EU-US Privacy Shield. The Swiss DPR aligns with the GDPR's principles, ensuring the continued flow of personal data between Switzerland and the EU.
Key Aspects of the Swiss DPR include:
- Consent and lawful basis: Similar to the GDPR, the Swiss DPR requires a legal basis for processing personal data, including consent, contractual necessity, and legitimate interests.
- Enhanced data subject rights: Individuals in Switzerland enjoy the rights to access, rectify, erase, and restrict the processing of their personal data.
- Cross-border data transfers: The Swiss DPR imposes restrictions on transferring personal data outside Switzerland, necessitating the use of adequate safeguards.
- Data Protection Officer (DPO): Certain organizations must appoint a DPO responsible for overseeing data protection activities.
- Data breach notification: Companies must promptly notify the Swiss Federal Data Protection and Information Commissioner (FDPIC) and affected individuals in case of a data breach.
Both GDPR and DPR apply to any organization, irrespective of location, that processes the personal data of individuals residing within their respective jurisdictions.
While the GDPR and Swiss DPR aim to protect individuals' privacy rights, organizations encounter various challenges when striving for compliance and effective data privacy management:
- Consent management: Obtaining valid consent and managing consent preferences across various jurisdictions and contexts is complex and resource-intensive.
- Data subject rights: Addressing data subject requests, including access, rectification, erasure, and restriction, within legally required timeframes often poses logistical challenges.
- Cross-border data transfers: Managing international data transfers, especially between the EU and Switzerland, requires navigating complex frameworks to ensure adequate safeguards and compliance.
- Data security and breaches: Protecting personal data from unauthorized access, implementing robust security measures, and promptly responding to data breaches demand significant investments in technology, expertise, and incident response protocols.
- Data privacy impact assessments: Conducting data privacy impact assessments (DPIAs) to identify and mitigate privacy risks associated with data processing activities can be time-consuming but crucial for compliance.
- Data governance and documentation: Establishing comprehensive data governance frameworks, documenting data processing activities, and maintaining proper records is often challenging, especially for organizations with large datasets and complex infrastructures.
The EU AI act and the UK-GDPR (ICO): navigating the regulatory landscape of AI and data privacy?
As artificial intelligence (AI) continues to advance and shape various industries, the need for robust regulations to govern its ethical use and protect data privacy has become increasingly pressing.
In April 2021, the European Commission proposed the AI Act - an ambitious legislative framework designed to set ethical standards for AI and strike a balance between fostering innovation and ensuring the protection of fundamental rights, including data privacy. The Act introduces a risk-based approach to AI regulation, categorizing AI systems into different levels of risk and imposing specific obligations accordingly.
Key Implications of the EU AI Act for Data Protection and Privacy:
- High-risk AI systems: The Act places stringent requirements on high-risk AI systems, including mandatory conformity assessments, transparency measures, and data governance provisions.
- Data protection impact assessments: Organizations developing or deploying high-risk AI systems are required to conduct data protection impact assessments (DPIAs) to identify and mitigate potential risks to data privacy.
- Prohibition of unacceptable practices: The EU AI Act prohibits AI systems that are considered unacceptable, such as those manipulating human behavior or engaging in social scoring based on prohibited grounds.
The recognition of synthetic data's importance is further highlighted by the new EU AI Act, proposed in May 2023.
In particular, Article 10 of the new AI Act specifies that high-risk AI systems must be developed using training, validation, and testing data sets that meet specific quality criteria, emphasizing the importance of data governance and preparation processes for these systems.
Additionally, Article 54 of the newly proposed AI Act mentions the further processing of personal data for developing certain AI systems in the public interest within the AI regulatory sandbox, where the use of anonymized, synthetic, or other non-personal data is deemed insufficient.
These explicit mentions of synthetic data within the regulatory framework reinforce the growing prominence of synthetic data and its role in various industries, particularly finance, healthcare, and insurance, where data privacy and security requirements often limit access to real-world datasets.
Meanwhile, following Brexit, the United Kingdom implemented its data protection regulations known as the UK-GDPR, regulated by the Information Commissioner's Office (ICO). The UK-GDPR is primarily aligned with the principles of the EU GDPR but incorporates some specific provisions to accommodate the country's unique regulatory landscape.
Alignment between the UK-GDPR (ICO), GDPR, and Swiss DPR:
- Shared principles: The UK-GDPR (ICO), GDPR, and Swiss DPR share common principles, including the protection of personal data, transparency, accountability, and individual rights.
- Complementary regulations: These regulatory frameworks work together to establish a comprehensive framework for data protection and privacy, ensuring consistency in data protection practices across the UK, EU, and Switzerland.
The UK-GDPR (ICO) aligns with the EU GDPR principles, as it was initially derived from the EU GDPR before Brexit. While there may be some nuanced differences to accommodate the UK's unique regulatory landscape, the core principles remain consistent, promoting a high standard of data protection and privacy.
Additionally, the Swiss DPR, Switzerland's data protection regulation, shares similar principles with the GDPR. Switzerland has implemented data protection laws that align with the EU GDPR to ensure the adequate protection of personal data in cross-border data transfers between the EU and Switzerland.
However, despite the alignment and harmonization efforts, there is still a need for ongoing efforts to establish more comprehensive regulations that effectively address the complexities of data protection and privacy in the context of AI. Companies operating in the UK, EU, and Switzerland should be aware of how these regulatory regimes intersect and complement each other to ensure compliance with data protection requirements.
Fortunately, synthetic data provides an effective solution to help companies navigate the complexities of data protection and privacy in the era of AI.
The Information Commissioner's Office (ICO), the UK's data protection regulator, has recognized synthetic data as a privacy-enhancing technology in its draft guidance on anonymization and pseudonymization. Synthetic data aims to weaken or break the connection between an individual in the original personal data and the derived data. This recognition emphasizes the potential of synthetic data in addressing privacy concerns while leveraging AI technologies.
What is synthetic data?
Synthetic data refers to data generated using artificial intelligence algorithms that mimic real-world data's structure, features, characteristics, and behavior. It is generated from scratch and does not contain any personal information, making it a powerful tool for companies seeking to comply with GDPR and other data privacy regulations.
By using advanced techniques like Generative AI and statistical modeling, synthetic data is created to mimic the patterns and distribution of real data. This makes it a perfect substitute for sensitive real-world data, eliminating the need to store, process, or use personal data in ways that violate GDPR and other data privacy regulations.
The generation process of synthetic data involves applying algorithms and models to create new data points based on observed patterns and relationships in real data. Techniques such as generative adversarial networks (GANs), generative pre-trained transformers (GPT) and variational autoencoders (VAEs) are commonly used in this process.
Once generated, synthetic data finds applications in various areas, including training machine learning models, testing software applications, augmenting datasets, and filling gaps in data where access to real data is restricted or limited.
The benefits of synthetic data for GDPR compliance and data privacy
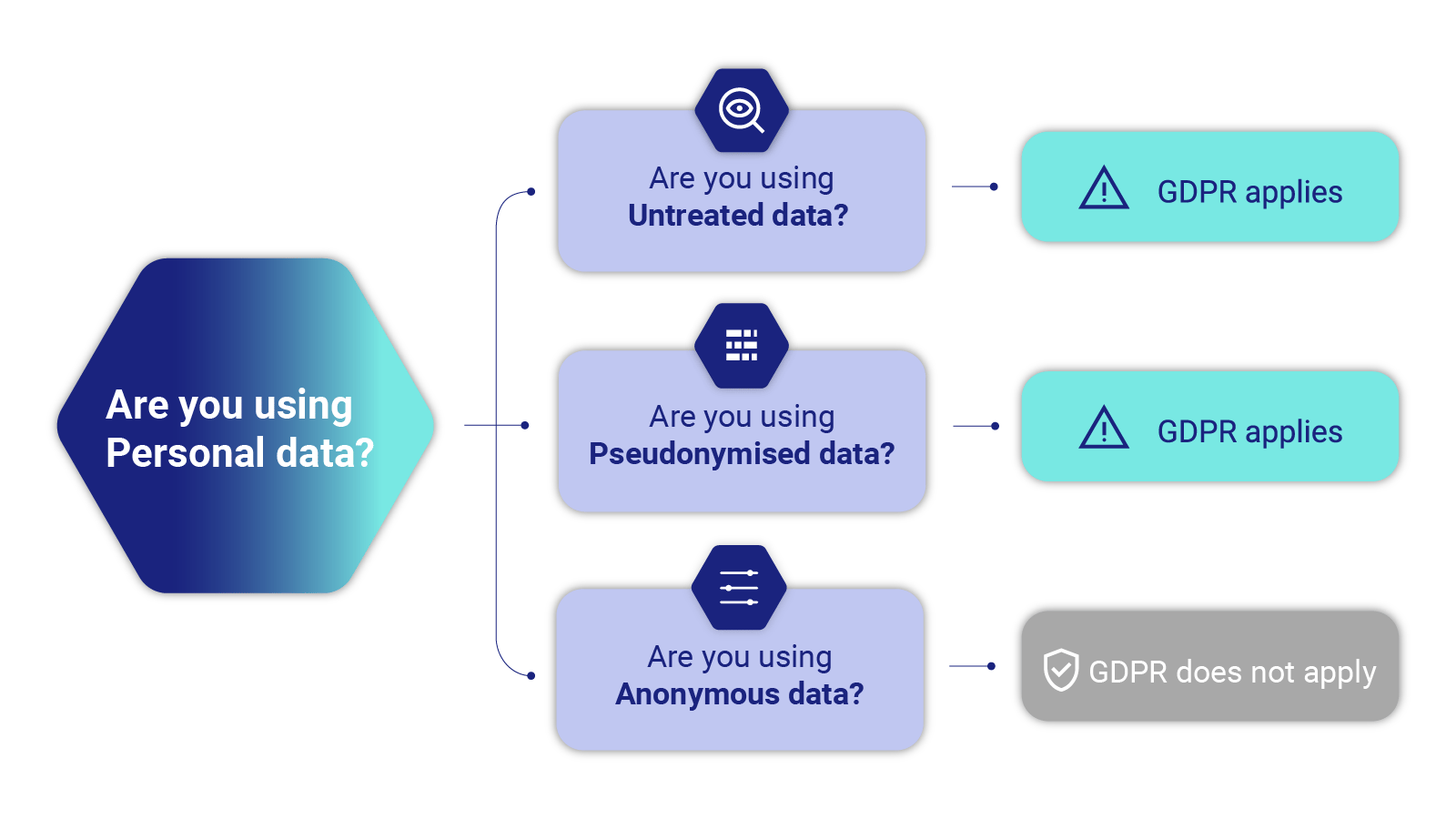
Before diving into synthetic data's benefits for GDPR compliance and data privacy, let's get some conceptual foundation: synthetic data is not the same as anonymized or pseudonymized data.
Anonymization is the process of removing personal data from a dataset to make it impossible to identify an individual directly or indirectly, either by the data controller alone or in collaboration with any other party.
Pseudonymization is a data management and de-identification procedure that replaces certain identifiers in a dataset with artificial identifiers or pseudonyms.
Unlike anonymization and pseudonymization, synthetic data doesn't try to obscure, modify, and/or encrypt the underlying data at all. Instead, it models the relationships and patterns that exist in real data and generates new datasets from scratch. If we compare it to anonymization and pseudonymization, it looks as follows:
Identifiability: While anonymization and pseudonymization aim to make data less identifiable, there is always a risk of re-identification, especially when dealing with large datasets or combining data from various sources. Synthetic data, being entirely artificial, mitigates this risk as it does not relate to real individuals, ensuring a higher level of privacy protection.
Data Utility: Anonymization and pseudonymization can significantly reduce the utility of data for certain applications, such as machine learning and advanced analytics, as important relationships and patterns may be lost during the process. Synthetic data, on the other hand, mimics the statistical properties and patterns of the original data, making it a more useful and representative alternative for various applications without compromising privacy.
Data Sharing and Collaboration: Anonymization and pseudonymization still carry some risks when sharing datasets with external parties, as there is a possibility of re-identification. Synthetic data mitigates this concern, providing a privacy-safe option for data sharing and collaborative efforts across organizations and research institutions.
Data Security and Breach Risks: Anonymized or pseudonymized data can still be susceptible to breaches, potentially exposing sensitive information. In contrast, synthetic data mitigates the risk of exposing real personal data, enhancing overall data security and reducing the impact of potential breaches.
To understand how it compares to anonymization and pseudonymization in regard to GDPR compliance and data privacy, let's look at the following graphic:
 If you're interested in diving deeper into the legal aspects, see the following resources on the most relevant EU regulations and guidelines:
If you're interested in diving deeper into the legal aspects, see the following resources on the most relevant EU regulations and guidelines:
Recital 26
Recital 26 of the GDPR encompasses significant statements that warrant attention:
1. Distinction between anonymization and pseudonymization: The recital highlights the difference between anonymization and pseudonymization, emphasizing that pseudonymization alone does not provide sufficient protection against privacy regulations.
2. Treatment of anonymous information: Recital 26 strongly asserts that the principles of data protection should not apply to anonymous information. It clarifies that the GDPR does not concern the processing of such anonymous information.
While these statements are strong, it's important to note the following considerations:
1. Non-binding nature: Recital 26 is not a binding provision in itself, serving more as explanatory text within the GDPR framework.
2. Ambiguity and use of "should": The use of the term "should" in Recital 26 introduces some degree of ambiguity, leaving room for interpretation.
3. Consideration of identification means: The recital acknowledges that all reasonably likely means of identifying a natural person should be taken into account, implying the need for a comprehensive assessment of potential re-identification risks.
While Recital 26 may have some nuances and uncertainties, additional EU writings provide valuable guidance in clarifying the criteria for determining when anonymization can effectively render a dataset exempt from privacy regulations.
These clarifications aim to establish a more comprehensive understanding of the implications of Recital 26, empowering organizations to navigate the landscape of data protection regulations effectively.
Article 29
The A29 Data Protection Working Party's Opinion 05/2014 is an extensive document that offers valuable insights into the criteria for anonymizing information, which aligns with the points mentioned in Recital 26. In its efforts to provide clarity, the document highlights the following:
1. Scope of anonymized data: A29 emphasizes that anonymized data fall outside the scope of data protection legislation, echoing some of the caveats mentioned in Recital 26 (p. 3). However, it adds the requirement for appropriate engineering in the application of anonymization techniques.
2. Identifiability of natural persons: A29 reiterates that the success of an anonymization technique lies in its ability to prevent the identification of a natural person.
3. Tests for identifiability: A29 lays out three detailed tests to assess whether a technique meets the standard for identifying a natural person. These tests examine the concepts of singling out, linkability, and inference.
4. Survey of anonymization techniques: The document provides a comprehensive overview of various anonymization techniques and evaluates their efficacy based on the three identifiability tests.
5. Best practices: A29 offers a list of best practices to follow when engineering an anonymization strategy.
The three identifiability tests mentioned in A29 are:
1. Singling out: The ability to isolate individual records or a group of records that identify a specific individual from a dataset.
2. Linkability: The ability to establish connections between at least two records related to the same data subject or group of data subjects.
3. Inference: The possibility of deducing the value of a particular attribute from the values of other attributes in a dataset.
A29 further discusses these tests in the context of various anonymization technologies.
Now that you have an understanding of the distinction between anonymization, pseudonymization, and synthetic data in terms of GDPR compliance and data privacy, let's look at the benefits of using synthetic data:
| Preserving data privacy |
One of the primary benefits of synthetic data is its ability to preserve data privacy. As it is generated from scratch and does not contain real personal information, synthetic data eliminates the risk of exposing sensitive data. This helps organizations comply with GDPR requirements regarding personal data protection and reduces the potential for data breaches or unauthorized access. |
| Mitigating identifiability risks |
Synthetic data generation techniques significantly reduce identifiability risks compared to anonymization or pseudonymization methods. By creating entirely new datasets with no direct or indirect links to real individuals, synthetic data mitigates the possibility of re-identification. |
| Enabling data analysis and testing |
Another benefit of synthetic data is its ability to provide a valuable resource for organizations to perform data analysis, testing, and research. This is particularly beneficial in scenarios where real data cannot be shared or used due to legal or privacy constraints. Synthetic data allows organizations to generate representative datasets that mimic real data's characteristics and statistical properties, enabling analysis and testing that otherwise wouldn't be possible. |
| Facilitating data sharing and collaboration |
Whether internally or with external stakeholders, sharing real data presents a significant risk of data privacy violations and unauthorized access. By replacing real data with synthetic versions, organizations get a privacy-friendly alternative, easily shared and used for collaborative purposes. Researchers, data scientists, and other stakeholders can work with synthetic data without risking sensitive information, opening up new opportunities for data sharing, collaboration, and knowledge exchange. |
| Improving data quality and reducing bias |
Real datasets may suffer from various limitations, including incomplete or biased data. Synthetic data generation techniques allow organizations to overcome these limitations by generating new datasets with controlled characteristics. Using synthetic data to balance class distributions, fill in missing values, or create specific scenarios that are underrepresented in the original data will ultimately improve the quality and accuracy of data-driven models. |
| Supporting model development and validation |
Synthetic data serves as a valuable resource for developing and validating models without using real data. Organizations train machine learning models or test algorithms on synthetic datasets to ensure their effectiveness and accuracy. |
In addition to the benefits outlined above, let's take a look at how synthetic data addresses specific GDPR requirements:
| Lawful basis for processing |
Under the GDPR, organizations must establish a lawful basis for processing personal data. By using synthetic data, companies avoid the need to process real personal data altogether, and organizations can bypass the requirement of obtaining consent or relying on other legal bases for processing. |
| Enhanced data subject rights |
The GDPR grants individuals enhanced rights over their personal data, such as the right to access, rectify, and erase their data. Synthetic data mitigates the risks associated with handling real personal data by eliminating the need to manage data subject requests. As synthetic data does not pertain to real individuals, there is no risk of violating data subject rights. |
| Data breach notification |
By utilizing synthetic data, companies minimize the impact of data breaches since synthetic data does not involve real personal data. This reduces the likelihood of breaching the GDPR's data breach notification requirements. |
| Privacy by design and default |
Synthetic data aligns well with the privacy by design and default principle as it enables organizations to work with privacy-friendly data devoid of personal information. Using synthetic data, companies can ensure privacy is embedded in their data-driven operations. |
| Data transfers |
As mentioned earlier, transferring personal data outside the EU is subject to restrictions under the GDPR. Synthetic data is a practical solution to circumvent the complexities associated with cross-border data transfers. Organizations are able to use synthetic data instead of transferring real personal data for various purposes, including training models or collaborating with international partners, without violating data transfer restrictions. |
Overall, synthetic data and GDPR compliance go hand in hand. Although the GDPR does not explicitly refer to synthetic data, it provides a data protection framework that organizations can use to ensure that their data-driven operations are compliant with the regulations.
EU-US privacy shield and synthetic data
When talking about data protection and privacy, we should also touch upon the EU-US Privacy Shield. The EU-US Privacy Shield was a framework established in 2016 to enable the transfer of personal data between the European Union (EU) and the United States while ensuring an adequate level of data protection. It provided a mechanism for US companies to self-certify their adherence to privacy principles aligned with EU data protection standards.
However, on July 16, 2020, the Court of Justice of the European Union (CJEU) invalidated the Privacy Shield framework in the "Schrems II" case. The court ruled that the Privacy Shield did not adequately protect the privacy rights of EU individuals when their data was transferred to the US due to concerns over US surveillance practices and a lack of remedies for EU individuals.
As a result, companies that relied solely on the Privacy Shield for transferring personal data between the EU and the US had to find alternative mechanisms to ensure compliance with EU data protection regulations.
Synthetic data presents an ideal solution in this context. By using synthetic data instead of personal data for transfers, companies alleviate the risks associated with international transfers while still ensuring data is used in a secure and privacy-compliant manner. This eliminates the complexity of obtaining consent or relying on other legal bases for transferring personal data to the US.
Moreover, synthetic data enables companies to demonstrate their commitment to protecting consumers' privacy, as it minimizes the risk of any personal data falling into the hands of malicious actors. This is especially beneficial for companies subject to strict privacy requirements, such as those in the healthcare and financial sectors.
The legal considerations of using synthetic data
Although synthetic data is an effective way for organizations to ensure GDPR and other data protection regulations are met, there are some legal considerations to keep in mind. Legally speaking, companies are still responsible for their data's accuracy, reliability, and completeness. This means that organizations should be aware of the potential risks associated with using synthetic data and ensure that their data is sufficiently accurate and reliable for its intended purpose.
Important legal considerations include:
- Establishing a clear governance process for the generation and use of synthetic data.
- Ensuring alignment between GDPR requirements and the data generation process.
- Making sure that the synthetic data produced complies with all relevant data protection regulations.
- Maintaining control over the synthetic data and who has access to it.
- Providing transparency about the use of synthetic data to customers and other stakeholders.
- Keeping track of the changes made to the synthetic data and ensuring they are in line with data protection regulations
Finally, since synthetic datasets are generated from real-world data, the risk of exposing private and sensitive information if the original data is not properly secured is always somewhat present. As humans are still involved in the data synthesis process, the potential for human bias and privacy issues cannot be ignored. Therefore, organizations must adhere to ethical standards, respect individual rights, and not violate applicable laws or regulations when using synthetic data.
Syntheticus recognizes both the potential and risks of using synthetic data. To ensure compliance with applicable laws, regulations, and ethical standards, Syntheticus is actively participating in the IEEE Standards Association, which has set up an IC Expert Group to set a standard for structured privacy-preserving synthetic data.
Conclusion
In the era of increased scrutiny and regulation around data protection and privacy, where using sensitive data introduces new hazards and risks almost daily, companies must take extra steps to ensure their data is secure and compliant.
Synthetic data emerges as a valuable solution for companies navigating the complexities of compliance and data privacy, beyond regulations like the GDPR and Swiss DPR. By relying on it, companies maintain an adequate level of data accuracy and reliability while mitigating privacy risks associated with data transfers, breaches, and malicious actors.
Although not perfect, synthetic data undoubtedly have a part to play in resolving the issues of data privacy and compliance. With its commitment to meeting ethical standards, Syntheticus is leading the way in providing secure and GDPR-compliant synthetic data solutions that enable companies to navigate the complexities of data protection and privacy, while seeking to balance innovation, compliance, and the protection of individual privacy rights.

