
Generate high-quality and compliant data samples at scale, built with GenAI.








.webp?width=285&height=285&name=RAW%20(1).webp)






AI and LLM are in constant need of more training data, creating tension between the desire for data and the limitations imposed by data privacy regulations.
While there's an ongoing demand for high-quality datasets, the truth is that real-world data is at maximum capacity. We’ve already scraped the entire internet, and we’re left with limited access to additional valuable information.
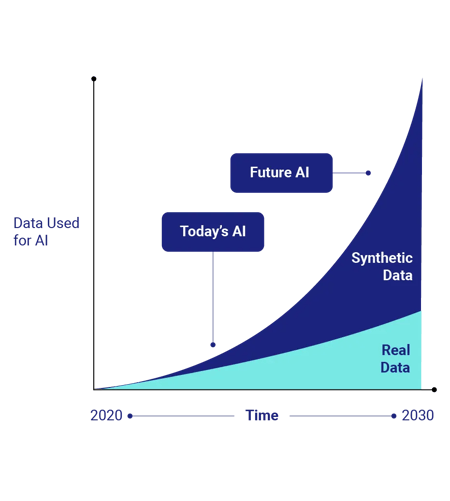
While advancements in AI and machine learning offer immense potential for businesses, they also raise concerns about data privacy. With GDPR, the EU AI Act, and other regulations, businesses must find ways to comply with global, regional, and national regulatory requirements.

That's why the United Nations, the EDPS, the White House, the Royal Society, the ICO, and others urge organizations to take advantage of the power of Privacy-Enhancing Technologies (PETs). PETs, including synthetic data, are there to keep your information safe while AI keeps evolving.

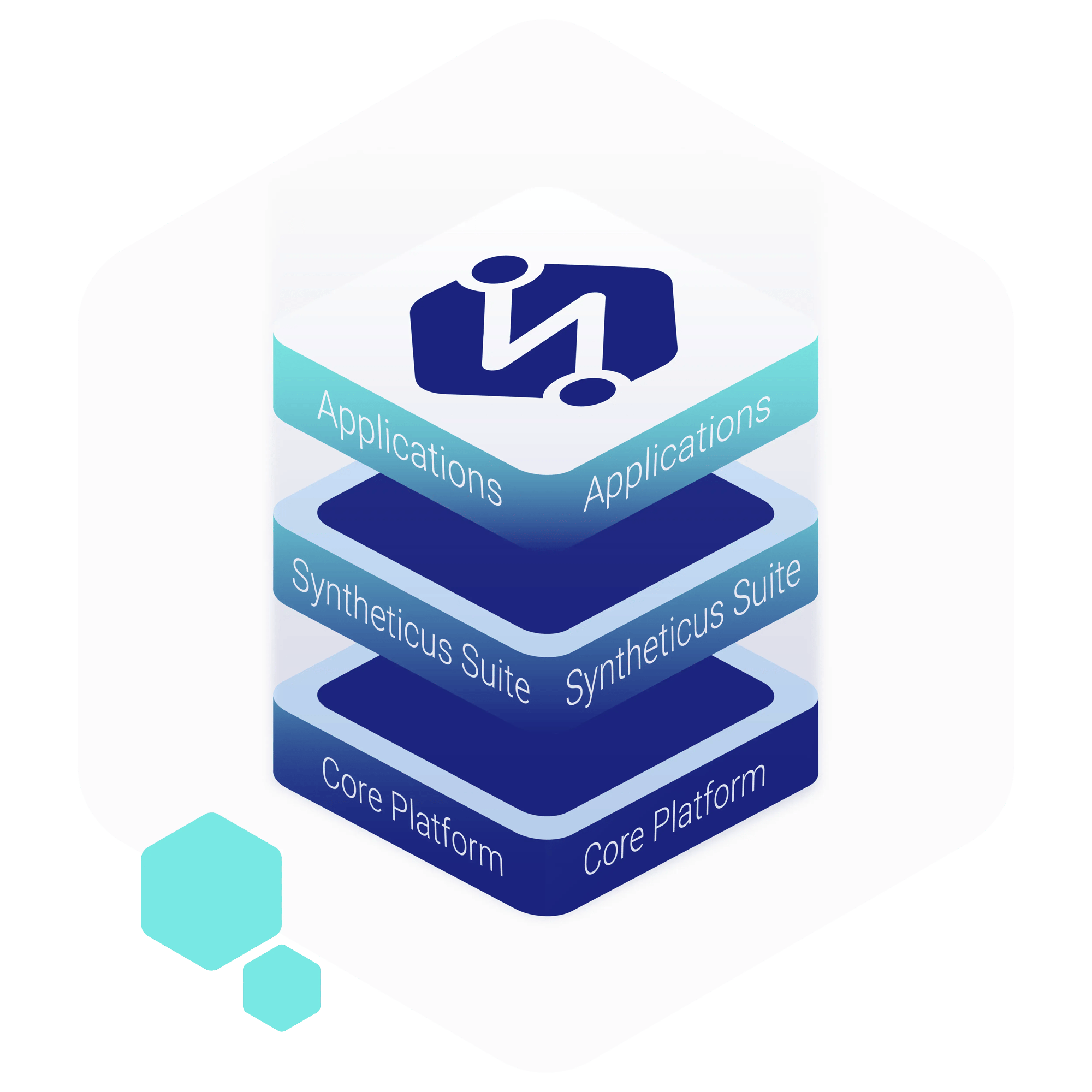
Engineered to bridge the gap between data availability and actionable insights, the Syntheticus Suite integrates a Core Platform with a set of advanced Functional Modules to supercharge innovative applications. Together, they form the ecosystem of Syntheticus.ai, empowering your data-driven initiatives.



Stay up to date with the latest blog posts and news from Syntheticus®


