Leveraging safe synthetic data to overcome scarcity in AI & LLM projects

In 2006, British mathematician Clive Humby famously stated that "data is the new oil." This analogy suggests that just like raw oil, data is not inherently valuable. It requires refinement, processing, and transformation into something useful in order to unlock its true potential and value.
In 2023, with artificial intelligence (AI) and large language models (LLM) being the driving force behind most technological advancements, data has become even more valuable. It is the fuel that powers AI algorithms and enables them to learn, make predictions, and make decisions.
But what if this fuel is in short supply?
Enter synthetic data, the solution that's reshaping the dynamics of AI and LLM projects. Synthetic data, for the uninitiated, is artificially produced data that mimics the characteristics of real-world data without directly corresponding to actual events or objects. It's like a stunt double for data, stepping in when the real-world data is unavailable, insufficient, or simply too expensive to acquire.
Data scarcity is a common obstacle in the AI landscape, interrupting innovation and limiting the scope of many promising projects. With synthetic data, however, this problem becomes far less daunting.
In this article, we will explore the concept of synthetic data generation and how it can counter data scarcity issues in AI and LLM projects. We'll investigate various techniques to generate synthetic data, evaluate its effectiveness, and navigate through the ethical and legal considerations associated with its usage.
Understanding synthetic data generation
Synthetic data is not new, but its application in AI and LLM projects has gained traction in recent years. This is due to the increasing demand for large and diverse datasets to train complex algorithms. Traditional data collection methods often fail to satisfy this need, making synthetic data generation a revolutionizing alternative.
The process of generating synthetic data involves creating artificial datasets that mimic the statistical properties, structure, and patterns of real-world data. This is achieved by using mathematical algorithms and models to generate new data points based on the existing dataset. In simpler terms, synthetic data is created by a computer, rather than being collected from real-world events or objects.
That allows researchers and developers to work with large, diverse datasets that are otherwise impossible to acquire. Synthetic data generation enables AI and LLM models to learn from more extensive datasets, thus improving their accuracy and performance. It also allows for the creation of new scenarios and edge cases that may not occur in real-world data but can be useful for training algorithms.
There are various techniques used for generating synthetic data and tools that make the process easier. Let's dive into some of them in the next section.
Techniques and tools for generating safe synthetic data
Techniques for synthetic data generation
At the heart of synthetic data lies the ability to create it programmatically. There are three major techniques you can opt for: machine learning-based models, agent-based models, and hand-engineered methods.
Depending on what you want to achieve and the type of data you require, several machine learning-based models can be employed. For instance, you can opt for Diffusion Models, Generative adversarial networks (GAN) or Variational Auto Encoders (VAE), which are great for creating synthetic time series, images, and even text data. On the other hand, the Gaussian Copula technique is great for handling data with a discrete distribution, such as the probability of certain events taking place. For language processing tasks, Transformer-based models like OpenAI's GPT are the top choice. Yet, they also have promising applications in various fields like computer vision and music generation.
If you're dealing with scenarios where individual agents impact the overall pattern seen in the data, then agent-based models like Traffic Simulation and Epidemiological Models come in handy. They simulate the behavior of individual entities within a system to generate useful synthetic data, whether for optimizing transportation systems or predicting disease outbreaks.
Last but not least, hand-engineered methods are a great choice when the underlying data distribution is well-known and can be represented using certain mathematical models. These include rule-based data generation, parametric models, random sampling, and linear interpolation.
Tools and emerging methods
In addition to the techniques mentioned earlier, several other emerging methods are proving beneficial in synthetic data generation. Transfer learning, for example, is gaining traction as an effective way to generate synthetic data. It involves leveraging a pre-trained model on a new problem. This approach is particularly useful when dealing with limited data as it allows the model to apply knowledge from one context to another.
Next, data augmentation involves creating new data by introducing minor transformations to the existing dataset, expanding the data variety without actually collecting new data. This approach is prevalent in image processing tasks, where the original images are transformed through rotations, flips, zooms, and other alterations to enhance the dataset's size and diversity.
Finally, the advent of open-source libraries and frameworks has democratized access to synthetic data generation. Libraries like `numpy` and `pandas` in Python provide powerful data manipulation and statistical functions that are invaluable in generating synthetic data. Similarly, frameworks like `TensorFlow` and `PyTorch` offer high-level APIs for building and training deep learning models, which are instrumental in synthetic data generation.
Overall, the choice of techniques and tools for synthetic data generation depends on the specific project's requirements and constraints. Data scientists must carefully evaluate and select the most suitable methods for their particular use case, keeping in mind factors like data type, volume, and complexity.
Why is synthetic data important for AI projects?
The reality is that AI and large language models are only as good as the data they are trained on. Without extensive, high-quality, real-world data, the effectiveness of these models is significantly compromised.
By creating varied, high-quality synthetic data, AI and large language models are trained more comprehensively and effectively. This data covers a much wider range of scenarios than real-world data, including edge cases and rare events that might be too scarce or even impossible to capture in the real world.
By 2024, Gartner estimates that 60% of data used for developing AI and analytics projects will be synthetically generated. But, like any other solution that fits within an AI stack, businesses also need to think of how synthetic data can best be integrated into a larger AI strategy.
Nearly half of the AI projects companies invest in never move beyond the proof-of-concept phase. Synthetic data techniques can unlock and dramatically accelerate AI, but that's meaningless if you can't get beyond the proof of concept and into production.
While it may make sense to first apply synthetic data to one high-need use case within your business, businesses should have a holistic AI plan in place before investing in any data acquisition strategy. This will ensure that the adoption of synthetic data is aligned with your company's broader AI goals and objectives, maximizing the return on your investment and paving the way for sustainable, long-term success in your AI initiatives.
Addressing data scarcity challenges
The scarcity of data is a critical bottleneck in building effective machine learning models. Models trained on limited data often suffer from overfitting, leading to sub-optimal performance when exposed to unseen data. This issue is prevalent in almost every industry, but can be particularly problematic in industries such as healthcare, finance, and rare event prediction.
The impact of data scarcity is felt throughout all industries and has tangible real-world implications. In healthcare, for instance, the lack of data about rare diseases can hinder the development of accurate diagnostic models, affecting patient outcomes. Similarly, in finance, limited data on market trends and consumer behavior can limit the effectiveness of predictive models, leading to poor investment decisions.
In such scenarios, synthetic data generation becomes a lifeline. By generating synthetic data points, we enrich the existing dataset, leading to improved model performance and robustness.
Customer success story: Enhancing diagnostic AI with synthetic data
A prime example of such a situation is diagnosing rare pathologies. These conditions are, by definition, infrequent, resulting in a scarcity of representative images for AI to learn from. This was the challenge faced by a recent customer project. Despite the extremely small amount of data provided, remarkable results were achieved.
The Challenge: Real-world data limitations
In the real-world dataset, the customer encountered significant limitations that hindered the development of effective diagnostic AI models. The dataset comprised a scarcity of high-quality images pertaining to rare pathologies, creating a notable lack of variability within the classes.
Specifically, the customer had a limited number of images across different classes, impeding the ability to train robust models capable of comprehensive pathology detection.
1. Image quantity: The dataset consisted of a sparse number of images, restricting the capacity to cover diverse pathology classes adequately.
2. Poor variability: Within the available images, the representation across various pathology classes was notably deficient, leading to insufficient model exposure and learning.
The solution:
The Syntheticus product, based on cutting-edge Diffusion models and specifically finetuned, augmented the existing data with synthetic images to overcome the resource gap.
The synthetic images were fed to the AI models, which used them to learn and improve.
The results:
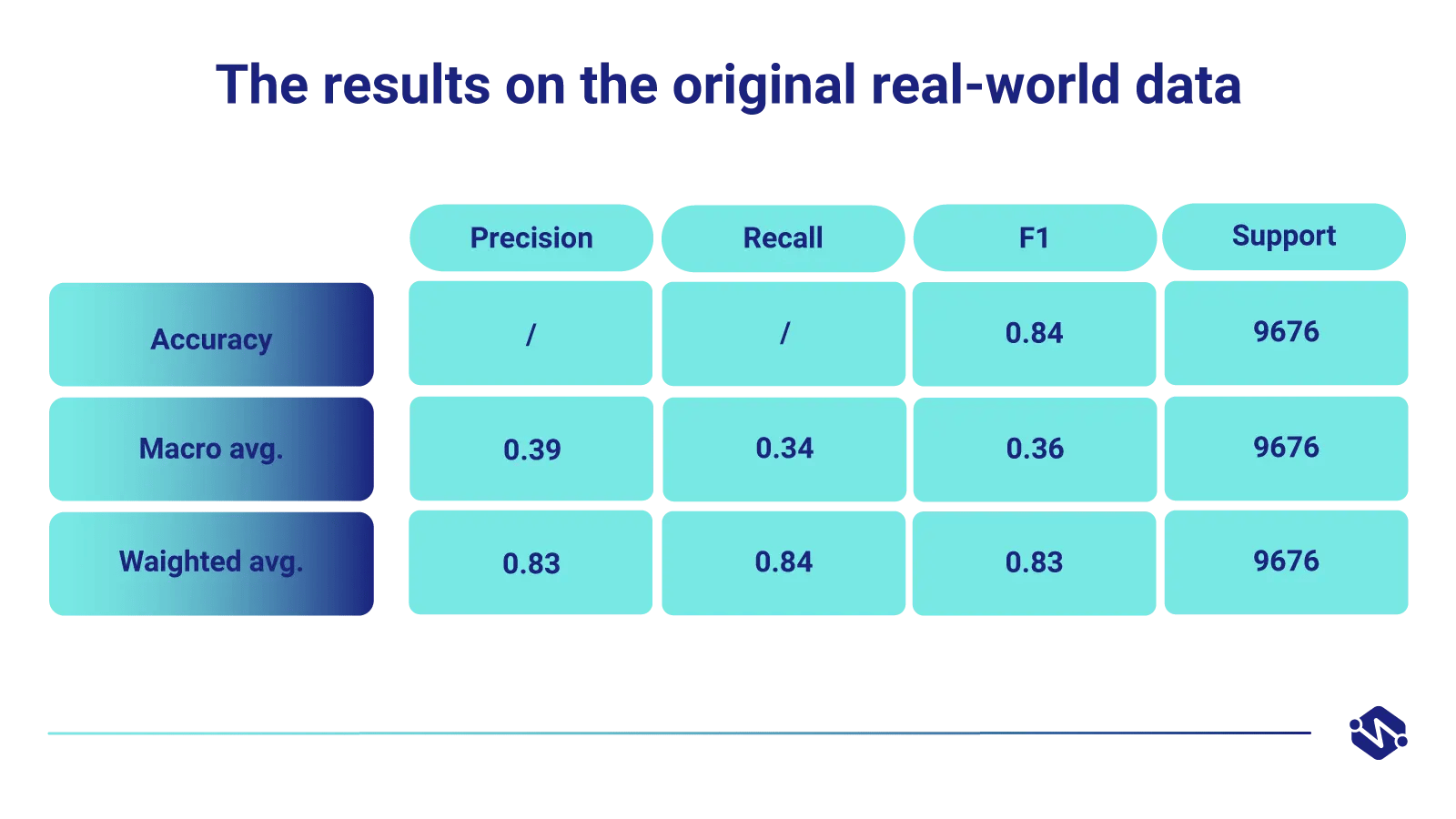
To illustrate the results, we will concentrate on the rare pathology Angiectasia. First the results on the original real-world data, second on the augmented synthetic data.
1. Test results on the original real-world data
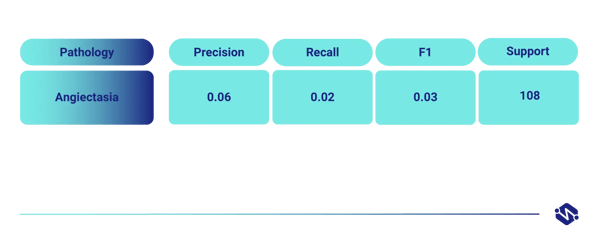
The dataset provided to us contained 866 Angiectasia images coming from 6 different patients. Due to its scarceness and low variability, a classifier trained on this data resulted in very poor performance.
This can be seen in the precision, recall, and F1 performance.
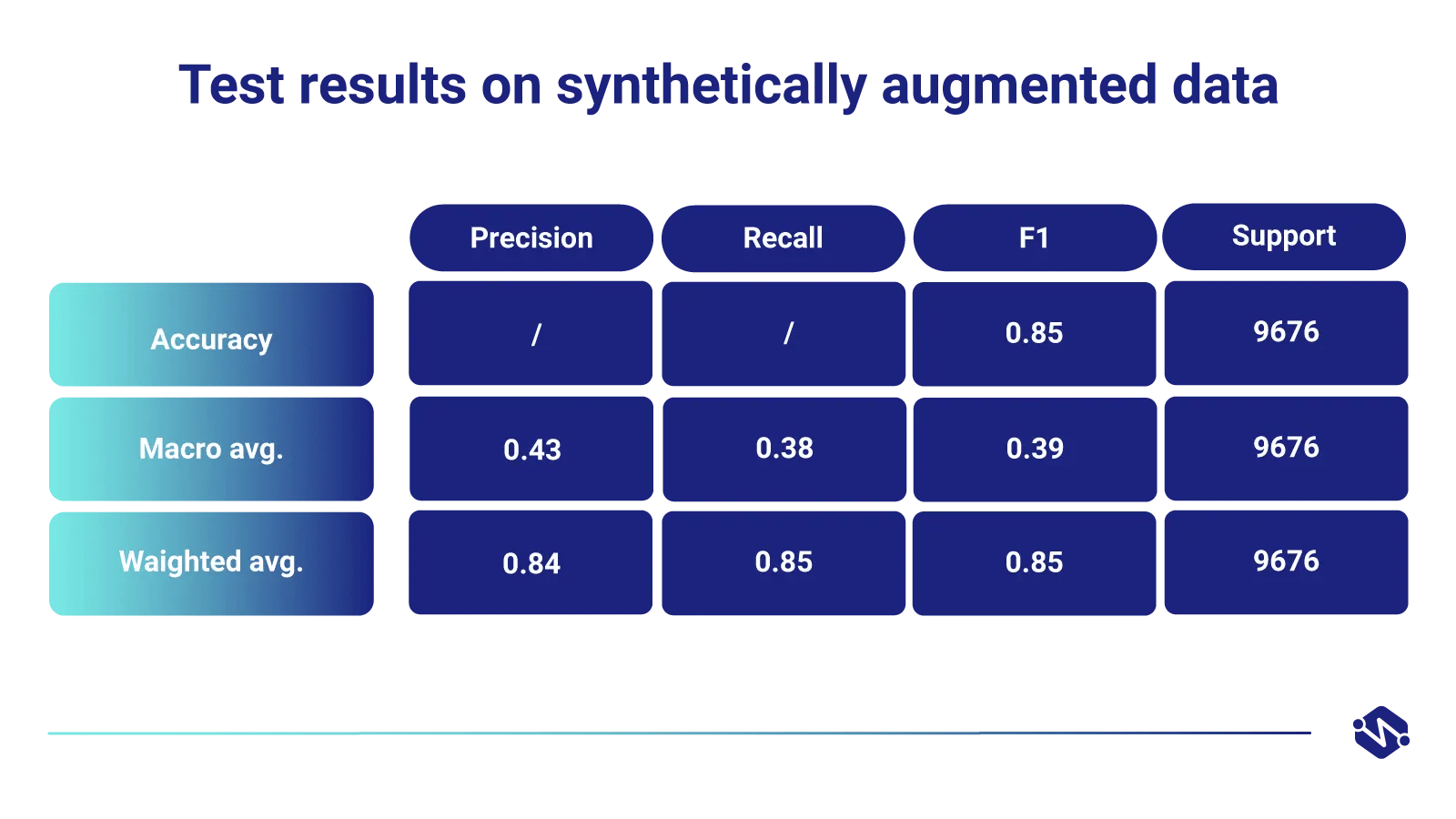
 2. Test results on synthetically augmented data
2. Test results on synthetically augmented data
After augmenting the 866 original images by +5000 synthetic images, the new classifier showed an almost 3x increase in precision, recall, and F1 when classifying this rare pathology.
 Furthermore, the augmentation of all rare pathologies led to an overall increase of model performance in accuracy, F1, precision, and recall.
Furthermore, the augmentation of all rare pathologies led to an overall increase of model performance in accuracy, F1, precision, and recall.
 Here are the graphical results. The 1st row shows the original real-world data, and below are 4 rows of GenAI-powered synthetic data samples:
Here are the graphical results. The 1st row shows the original real-world data, and below are 4 rows of GenAI-powered synthetic data samples:

Discussion:
Despite the extremely small amount of data provided to us, the Syntheticus product achieved remarkable results. There is an overall classifier improvement, however some rare pathologies get better, some get worse. This can be explained by the small variability of the real-world data - in some cases the rare pathology images derive only from one video from one patient.
Overall, this customer success story stands as a testament to the versatility of synthetic data generation, showcasing its potential not only in healthcare but also across diverse industries where data scarcity challenges impede AI advancements.
Evaluating and validating synthetic data
Now that you have a better understanding of synthetic data, it's important to note that not all of it is created equal. So before you use it in your AI and LLM projects, implement strategies that ensure the synthetic data's quality and usefulness. These strategies should consider the unique risks and accuracies associated with various synthetic data techniques.
Best practices for quality assurance in synthetic data generation
|
Invest in data quality checks |
Implement checks and balances to identify inconsistencies, inaccuracies, and errors in the datasets before generating synthetic data. This could involve visual inspection of the source data and the use of automated tools for potential issue detection. |
| Use multiple data sources |
Leveraging multiple data sources enhances the accuracy of synthetic datasets. It provides additional context or detail and reduces bias that may occur when relying on a single data source. |
| Validate generated synthetic data |
Implement quality assurance practices to test synthetic data for accuracy, consistency, and reliability. Use automated tools to check for discrepancies between the generated and real-world datasets. That will enable you to detect potential issues before deploying synthetic datasets. |
| Regularly review synthetic datasets |
Even after validation, periodically review synthetic datasets to ensure accuracy and identify any issues that may have arisen due to changes in the source data or the synthetic data generation process. |
| Implement model audit processes |
Assess the performance and efficacy of AI models to ensure synthetic data quality. A model audit process provides insight into the data, its processing, and how the synthetic dataset is used. It helps detect bias or errors in the synthetic data and facilitates corrective actions when needed. |
Evaluating synthetic data quality
Having implemented the necessary measures to ensure high-quality synthetic datasets, it's important to evaluate their efficacy. Synthetic data is assessed against three key dimensions: fidelity, utility, and privacy.

Fidelity metrics: They are used to compare the properties of the original data and the synthetic dataset to measure their similarity. The higher the metric score, the greater the fidelity of the synthetic dataset.
Utility metrics: They measure the performance of the synthetic dataset on downstream tasks. Higher scores indicate better performance of the synthetic dataset compared to the original one.
Privacy metrics: These measure how well the synthetic data conceals private information. A synthetic dataset with high utility but a low privacy score may lead to privacy violations.
While evaluating synthetic data's privacy properties, it's essential to consider both utility and privacy scores. A tradeoff exists between fidelity, utility, and privacy. Data can't be optimized for all three simultaneously - therefore, you must prioritize what is essential for each use case and manage expectations from the generated data.
Currently, there is no global standard for assessing quality regarding privacy, utility, or fidelity. Quality needs to be assessed on a per-use-case basis to ensure that generated synthetic datasets are suitable for the intended purpose.
Conclusion
Dealing with real-world datasets in your AI projects often comes with its fair share of difficulties, primarily due to their propensity to contain skewed, scarce, or biased data.
This is an issue that impedes the overall performance of your AI models and leads to inaccurate predictions, which can have serious consequences in many industries.
However, thanks to the advancements in technology and the emergence of synthetic data generation techniques, you now have a solution that solves the problems of data scarcity and bias in AI and LLM projects. The dynamic combination of GenAI-powered synthetic data and AI will change the data landscape as we currently know it and will revolutionize the way we approach data-driven projects and overcome the challenges posed by real-world datasets. No doubt, the future of synthetic data looks promising.

