Lifting data barriers: exploring synthetic data in healthcare research

The rapid digitization of healthcare has brought significant advancements and opportunities in the field of medical care and research. In many ways, the availability of digital health data has revolutionized the way clinicians treat and diagnose patients, allowing for more accurate diagnoses and treatment plans. It has also enabled healthcare researchers to identify patterns and trends in the data, used to better understand disease progression, outcomes, and treatments.
However, despite the surge in funding for digital healthcare since the pandemic, there remains a substantial gap between digital leaders and life sciences. According to a recent survey by McKinsey, the primary challenge hindering the digital performance of MedTech and pharma companies is the lack of a high-quality, integrated healthcare data platform.
This deficiency in data access poses a significant barrier to realizing the potential of applied artificial intelligence (AI), industrialized machine learning (ML), and cloud and edge computing, which receive substantial investments from these companies. Without access to sufficient quantities of reliable data, these investments are limited in their ability to generate tangible outcomes.
Fortunately, healthcare researchers now have the option to explore synthetic data use in research. Synthetic data is data generated by computers, used to train AI models. It has the potential to revolutionize healthcare research, providing healthcare researchers with a promising solution to the data access challenges they face and offering representative patient data while ensuring privacy protection.
Understanding data barriers in healthcare research
In the realm of healthcare research, the availability of high-quality data is of paramount importance. It serves as the foundation for understanding disease patterns, identifying effective treatments, and improving patient outcomes. However, accessing and utilizing real-world healthcare data for research purposes poses significant challenges and limitations, impeding progress in the field.
One of the primary challenges in accessing healthcare data for research is the issue of privacy concerns and legal restrictions. Patient data is highly sensitive and subject to strict regulations to protect individual privacy rights. The Health Insurance Portability and Accountability Act (HIPAA) in the United States, General Data Protection Regulation (GDPR), and similar regulations in other countries impose stringent requirements on collecting, using, and sharing personal health information. As a result, healthcare providers and researchers are limited in their ability to access, use, and share healthcare data, limiting research collaboration and the advancement of medical knowledge.
Another significant challenge lies in the concept of secondary usage of healthcare data. While patient data is primarily collected for clinical purposes, it holds immense value for research and innovation. However, repurposing this data for research requires navigating complex legal and ethical considerations. Consent issues, data anonymization, and data security pose huge obstacles for healthcare researchers wishing to use existing data sources or create new datasets.
Finally, the collection of healthcare data is a time-consuming and expensive process. It takes months to collect, clean, and analyze enough data to identify meaningful trends or patterns. This challenge is further compounded by the fact that many healthcare providers are unable to access the capital or resources necessary to invest in data collection and management.
The European Health Data Space (EHDS) is an example of a major initiative that aims to address some of these challenges by creating a health-specific ecosystem comprising rules, common standards and practices, infrastructures, and a governance framework.
Its primary goals include empowering individuals through increased digital access to their electronic personal health data, both at the national level and EU-wide, and supporting the free movement of such data. Additionally, the EHDS aims to foster a genuine single market for electronic health record systems, relevant medical devices, and high-risk AI systems.
By establishing common standards and practices, the EHDS aims to facilitate the secondary use of health data while ensuring privacy protection and data security. This initiative seeks to create a robust framework that enables researchers to access and utilize health data in a reliable and standardized manner.
Despite these efforts, challenges remain in implementing the EHDS and overcoming data barriers in healthcare research. Technical interoperability issues, data quality concerns, and harmonization of data formats across different healthcare systems are just some of the ongoing challenges for healthcare researchers. In addition, the cost of data collection and management remains a significant barrier, particularly for smaller healthcare providers and research institutions.
Synthetic data as a solution
What is synthetic data?
In the introduction, we briefly mentioned synthetic data as a potential solution to data collection challenges, privacy protection, and resource constraints. Here we will explore what synthetic data is and how it is used to overcome the mentioned barriers to healthcare research.
Synthetic data is artificially generated data that mimics the structure and properties of real-world data. It is created using mathematical models and algorithms to generate realistic datasets without compromising privacy.
The core value of synthetic data lies in its ability to provide concrete and representative insights from sensitive data while minimizing the risk to patient privacy and limiting governance requirements. Synthetic data offers a viable solution where sharing identified or de-identified data is challenging or even impossible.
For instance, consider a pharmaceutical company based in the United States that has developed a commercial treatment for cancer. The company wishes to understand the course of treatment and outcomes for patients with the same cancer in the European Union (EU) to prepare for market entry.
However, under the General Data Protection Regulation (GDPR), sharing patient-level data from the EU poses some privacy and legal hurdles. By creating a synthetic version of the EU patient data, the company will access and analyze the synthetic data without the need for the same level of overhead, ensuring compliance with privacy regulations and saving valuable time and resources.
Applications of synthetic data in healthcare research
Synthetic data has a range of applications in healthcare research, and one of the primary ones is training machine learning models. Machine learning algorithms require large volumes of diverse and representative data to learn patterns, make accurate predictions, and extract valuable insights.
Synthetic data is used to generate additional training data, augmenting the limited real-world datasets and expanding the learning capabilities of these models. By incorporating it, researchers enhance the performance and generalizability of machine learning models, enabling more accurate predictions and facilitating the development of innovative healthcare solutions. Researches also leverage synthetic data to develop robust predictive analytics tools for disease prediction, treatment planning, and healthcare resource allocation.
For example, a healthcare provider can use predictive modeling to accurately predict the progression of chronic diseases such as diabetes and identify patients likely to need additional or early interventions. By leveraging synthetic data, the healthcare provider develops and tests models without accessing or collecting sensitive patient information, ensuring compliance with regulatory guidelines and maximizing privacy protection.
Synthetic data also plays a significant role in population health analysis for policy-making, as it is used to model and analyze various population health factors, including disease outbreaks, demographics, and risk factors. That enables policymakers to make informed decisions by providing insights into the potential impact of different interventions and policies.
Data repurposing for research and development is another valuable application of synthetic data. As mentioned earlier, regulatory limitations often prevent the secondary use of data for research purposes. Synthetic data provides a solution by acting as a drop-in replacement, supporting research and development efforts without compromising privacy or regulatory compliance.
In clinical trials, researchers can use synthetic data to create a so called “synthetic control arm”. Instead of recruiting patients to sign up for trials to not receive the treatment (being the control group), they can turn to an existing database of patient data. This approach has been effective for interpreting the treatment effects of an investigational product in trials lacking a control group, and it is particularly relevant in rapidly evolving fields like digital health, where iterative testing and development are crucial.
Another example of synthetic data in healthcare research is its use for clinical trial simulations. Clinical trials evaluate new treatments and medications and assess their efficacy, safety, and potential side effects. However, they are often expensive and time-consuming to conduct, and the sample size may not be large enough to generate statistically important results.
By using synthetic data to simulate clinical trials, researchers generate large volumes of data within minutes, enabling them to assess the efficacy of potential treatments without having to conduct costly trials. In addition, it allows researchers to explore a range of "what-if” scenarios, enabling them to assess the impact of various treatments on different populations.
Finally, synthetic healthcare data is used to generate real-world evidence (RWE), which is evidence generated from observational studies and the analysis of existing datasets. This type of evidence is used to inform decisions regarding healthcare treatments' safety, efficacy, and effectiveness.
By leveraging synthetic data, researchers create simulations based on existing real-world evidence and explore the impact of different treatments on various populations. This enables them to assess a range of treatment options in a safe and secure environment without accessing sensitive patient data.
Benefits of synthetic data in healthcare research
Using synthetic data for healthcare research brings many benefits, including privacy protection, data availability, scalability, research collaboration, reproducibility, and addressing issues related to data bias and representativeness.
Privacy protection: Synthetic data provides a secure and privacy-preserving approach to healthcare research, enabling researchers to access and analyze datasets without compromising patient privacy. Its generation techniques make it extremely challenging or nearly impossible to trace the synthetic data back to the original patient, enabling researchers to explore sensitive datasets without fear of breaching regulations.
Data availability: Synthetic data overcomes the barriers of legal restrictions, consent requirements, and data sharing challenges. Generating synthetic datasets that closely resemble the original data, provides researchers with a wider pool of data to work with. This increases data availability and opens up new avenues for research, enabling them to explore larger sample sizes, conduct in-depth analyses, and derive more accurate and reliable insights.
Scalability: Traditional data collection methods are often time-consuming, expensive, and logistically challenging. Synthetic data generation, on the other hand, allows for the creation of large-scale datasets with minimal effort.
Research collaboration and reproducibility: Privacy concerns, legal complexities, and data ownership issues all impede research collaboration and reproducibility. By using synthetic data, researchers readily share datasets without worrying about patient privacy or data breaches. This facilitates research collaboration, allowing scientists to collaborate and build upon each other's work.
Additionally, synthetic data contributes to reproducibility by providing a standardized and controlled dataset shared and used by other researchers to validate research findings and ensure the transparency and robustness of scientific investigations.
Addressing data bias and representativeness: Finally, synthetic data helps researchers address data bias and representativeness issues. Real-world healthcare datasets may suffer from biases due to factors like demographic imbalances, regional variations, or data collection inconsistencies.
Synthetic data generation techniques mitigate these biases by creating balanced and representative datasets that capture a wide range of patient characteristics and scenarios. This enables researchers to develop models and insights that are more robust, generalizable, and applicable to diverse populations, leading to improved healthcare outcomes and equitable treatment approaches.
Synthetic healthcare data types
In healthcare, a wide variety of data types is generated using synthetic data generation techniques. Image data, such as medical imaging scans, has been at the forefront of medical advancements, enabling more accurate diagnoses and AI-powered surgical guidance systems.
However, the potential of artificial intelligence extends beyond image analysis.
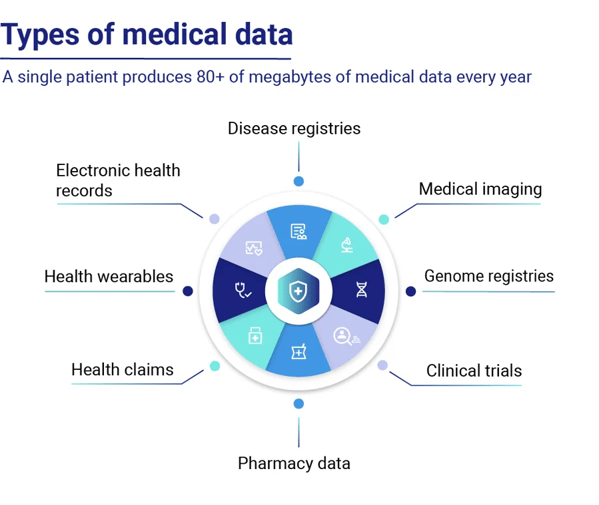
Source: Huesch, D., and Mosher, T. J. (2017). Using It or Losing It? The Case for Data Scientists Inside Health Care. NeJM Catalyst. Available online at: https://catalyst.nejm.org/case-data-scientists-inside-health-care/
Tabular healthcare data, including electronic health records (EHR), electronic medical records (EMR), lab results, and data from monitoring devices, holds immense value for AI applications in healthcare. Synthetic data generated through AI training on real datasets has emerged as a versatile tool with numerous use cases. It allows researchers to collaborate across borders and institutions, overcoming data-sharing limitations and privacy concerns.
Rare disease research often faces challenges due to limited data availability, as disease prevalence is low, and thus many datasets are incomplete or difficult to access. Additionally, sharing datasets across national borders and research teams can be complex and time-consuming.
Synthetic data generated from existing datasets and simulations helps researchers overcome these challenges, enabling them to access larger sample sizes and explore new avenues of research, bypassing compliance issues and privacy risks. This facilitates faster advancements in rare disease research at a lower cost, improving patient outcomes.
Moreover, onboarding researchers and scientists to healthcare data platforms populated with synthetic data is straightforward, as it does not legally qualify as personal data, streamlining collaboration and knowledge exchange.
Challenges and ethical considerations in using synthetic data
While synthetic data offers promising solutions for overcoming data access barriers in healthcare research, several challenges and ethical considerations still need to be addressed.
These challenges include the need for proper validation and evaluation methods, concerns about the generalizability of findings, and regulatory and ethical considerations surrounding the use of synthetic data.
Validation and evaluation
You can’t ensure synthetic data’s usefulness in research before you validate its quality and reliability. Proper validation methods must be used to assess synthetic data's accuracy, correctness, and representativeness. In addition, appropriate evaluation measures must be employed to evaluate the efficacy of data synthesis techniques, measure the performance of machine learning models trained on synthetic data, and compare them to models trained on real data.
Generalizability of findings
Generalizability means the extent to which research findings can be generalized or applied to other contexts. While synthetic data provides valuable insights, there may be some limitations in its ability to fully capture the complexity and diversity of real-world data.
The generalizability of research findings derived from synthetic data should be carefully considered and validated to ensure their applicability to real-world scenarios. Researchers must be cautious in extrapolating findings from synthetic data to the broader population or making critical decisions based solely on synthetic data results.
Regulatory and ethical considerations
As it’s probably obvious by now, the use of synthetic data in healthcare research is subject to regulatory frameworks and ethical considerations. Compliance with data protection regulations, such as GDPR in the European Union and HIPAA in the United States, is essential to safeguard patient privacy and ensure the lawful use of data.
Ethical considerations, such as ensuring data is being used for legitimate research purposes and not to harm any individuals or groups, also need to be taken into account. Informed consent, data ownership, and transparency are other important factors that must be carefully addressed when generating and utilizing synthetic data.
Guidelines and frameworks
Recognizing the importance of responsible use of synthetic data, ongoing efforts are being made to establish guidelines and frameworks for its ethical and regulatory governance. International organizations, research institutions, and regulatory bodies are working towards developing standards and best practices to ensure the transparent, accountable, and ethical use of synthetic data in healthcare research.
These efforts aim to strike a balance between data accessibility and privacy protection, ensuring that synthetic data is used responsibly and ethically to advance medical knowledge and improve patient care.
Since the lack of clear standards on privacy metrics can create uncertainty around how to best protect sensitive information in synthetic datasets, Syntheticus is actively participating in the IEEE Standards Association, which has set up an IC Expert Group to set a standard for structured privacy-preserving synthetic data.
As synthetic data continues to gain momentum in healthcare research, it is essential to create standards and best practices that safeguard patient privacy, protect data rights, and ensure synthetic data's legitimacy, accuracy, and reliability.
Future directions and conclusion
Looking ahead, the future of synthetic data in healthcare research looks promising as advancements in generation techniques continue to capture the complexity of real-world data with more accuracy. This will enable researchers to accelerate medical discoveries, bypass privacy and data-sharing limitations, and enhance collaboration across institutions.
The key to unlocking the full potential of synthetic data lies in developing standards, frameworks, and best practices that guarantee patient privacy and ensure the validity and accuracy of synthetic datasets, which makes collaboration between researchers, policymakers, and regulatory bodies crucial. These guidelines should address concerns such as data privacy, informed consent, and transparency, instilling confidence in both researchers and the public regarding the use of synthetic data.
Furthermore, efforts to enhance data interoperability, standardization, and data-sharing infrastructure will play a significant role in facilitating the widespread adoption of synthetic data in healthcare research. By improving the accessibility and compatibility of healthcare data, researchers will easily collaborate, exchange insights, and build upon each other's work, ultimately driving progress in medical discoveries and treatments.
In conclusion, synthetic data has the potential to revolutionize healthcare research by providing an innovative solution to data access challenges while safeguarding patient privacy. With rigorous validation, ethical considerations, and regulatory frameworks in place, synthetic data fosters collaboration, enables reproducibility of research findings, accelerates breakthroughs in medical science, and ensures a brighter future for healthcare research.

