Tackling bias in large ML models: the role of synthetic data

The rapid advancement of machine learning (ML) and artificial intelligence (AI) has led to the development of large ML models with impressive capabilities. These models have proven to be excellent tools for analyzing vast datasets and achieving remarkable accuracy in challenging tasks, ranging from face recognition to credit scoring. Their potential to revolutionize virtually any industry is undeniable.
However, these large ML models are not without their flaws. One of the most significant concerns is the presence of bias in their outputs. Bias in ML models can arise from various sources, including biased training data, biased algorithms, and biased decision-making processes. When left unchecked, they easily reinforce existing societal prejudices and disparities, particularly in sensitive areas like crime prevention and healthcare.
In this blog post, we will explore the problem of bias in large ML models and the role that synthetic data plays in addressing this issue. We will discuss why bias in ML models is a problem, the different sources of bias and their effects, and the implications of using synthetic data in large ML models.
Understanding bias in large ML models
At its core, bias in machine learning models is a form of algorithmic discrimination. This occurs when an algorithm or data set is trained to identify patterns in specific categories of data, resulting in the formation of inaccurate or incomplete generalizations that lead to unfair distributions of outcomes. Bias can also be introduced when data is collected using non-representative sampling or when the algorithms used to process the data are inherently biased.
In large ML models, bias is especially problematic. That's because these models are often trained on massive datasets that contain millions of training examples. This makes it challenging to identify and address potential sources of bias in the data. Additionally, large ML models often rely on complex algorithms that produce results that are difficult to interpret, which makes it harder for developers and users to identify and address potential sources of bias in the algorithms themselves.
Definition and types of bias in large ML models
Bias in large ML models can manifest in various forms, impacting the accuracy and fairness of their outputs. Some common types of bias include:
- Algorithm bias: Occurs when there are issues within the algorithm itself, leading to biased computations and predictions.
- Sample bias: Arises from problems with the data used to train the ML model. Inadequate or non-representative training data can lead to skewed results.
- Prejudice bias: Results from using data that reflects existing prejudices, stereotypes, and societal assumptions, perpetuating real-world biases in the ML model.
- Measurement bias: Stemming from inaccuracies in data measurement, this bias affects the quality and accuracy of the ML model's outcomes.
- Exclusion bias: Occurs when important data points are left out during training, potentially leading to incomplete or biased conclusions.
- Selection bias: Arises when training data is not sufficiently large or representative, resulting in biased performance and accuracy.
- Recall bias: Develops during the data labeling stage, where subjective observations lead to inconsistent labeling.
Examples of biased large ML models and their implications
To better grasp the impact of bias in large ML models, let's consider an example related to credit scoring. If a person lives in a poor neighborhood, an ML model might associate their credit score as risky, assuming it is similar to most individuals in that area. This guilty-by-association bias will result in unfair credit assessments and perpetuate financial disparities.
The COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) algorithm, utilized in US court systems to estimate the probability that a defendant will be a reoffender, is the most prominent example of an ML model with serious bias. The algorithm was found to be twice as likely to falsely flag black defendants than white ones, leading to unjust incarcerations for individuals from specific demographics.
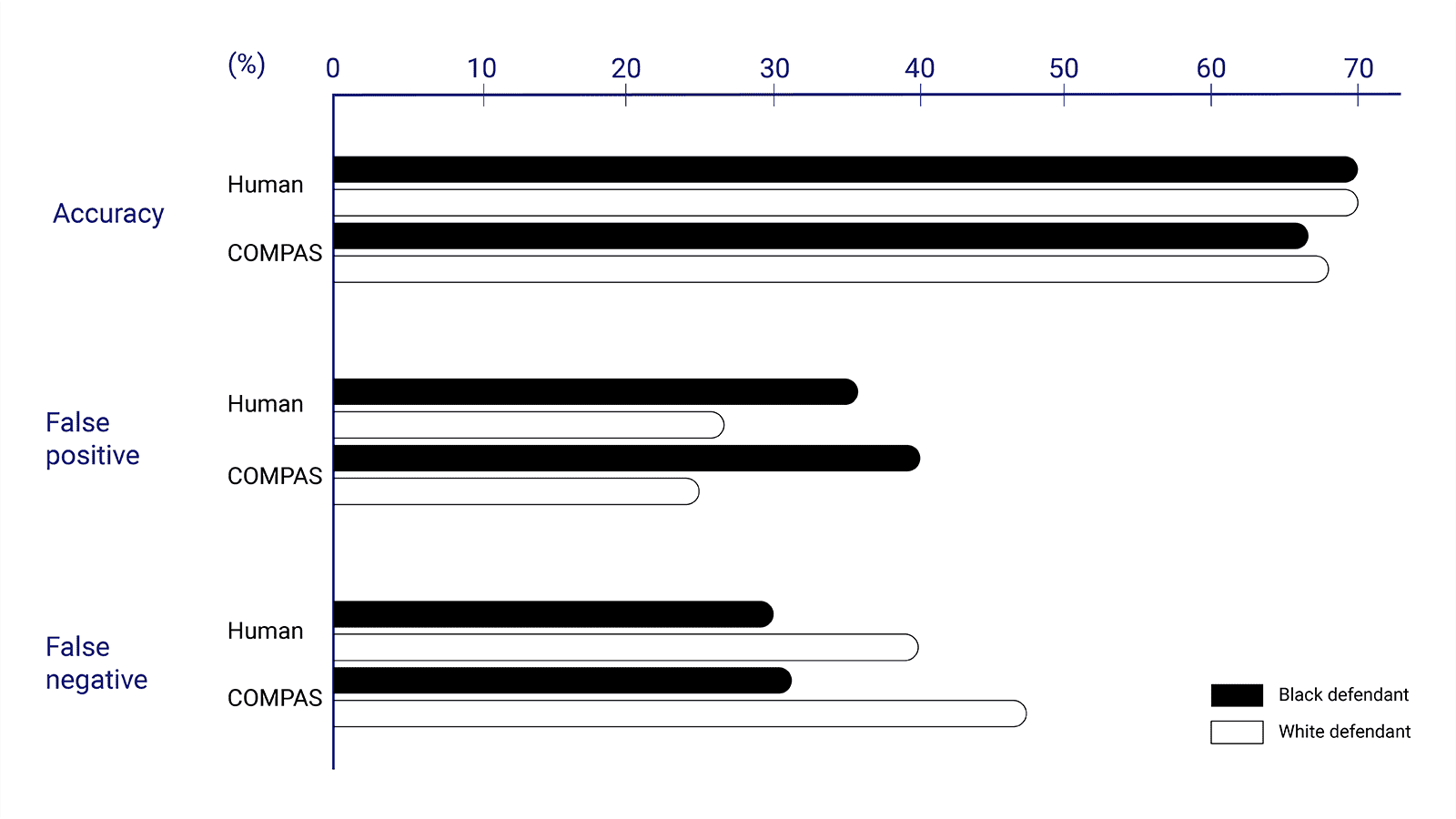
Source: Dressel, J., and Farid, H. (2018). The accuracy, fairness, and limits of predicting recidivism. Available online at: https://www.science.org/doi/10.1126/sciadv.aao5580
These examples demonstrate the severe implications that result from bias in large ML models, therefore, addressing this bias requires a thoughtful approach. Removing sensitive features like location, race, or gender might seem like a solution, but it can lead to less accurate models and create unintended side effects. For instance, not including gender in car insurance calculations might harm women, who statistically have fewer accidents and deserve lower premiums.
An alternative solution involves augmenting the dataset with additional relevant features, such as education level and owned property. By considering a broader range of attributes, the model makes more informed and less biased credit risk decisions.
Moreover, it's crucial to recognize that all ML models inherently contain some level of bias since their purpose is to discriminate based on specific attributes. However, not all biases contribute significantly to the model's accuracy, and mitigating harmful biases is essential for promoting fairness.
Challenges in detecting and addressing bias in large ML models
Bias can indeed be introduced at various stages of the ML pipeline, potentially leading to unintended consequences. If the machine learning pipeline you're using contains inherent biases, the model will not only learn but also exacerbate them.
Therefore, identifying, assessing, and addressing potential biases impacting the outcome is crucial when creating a new ML model. Let's look at the whole ML pipeline and the different biases involved in each phase. The standard machine learning project pipeline consists of the following steps:
Data collection
Data collection is the foundational step in the machine learning pipeline and sets the stage for the entire process. However, biases can be introduced during data collection. For instance, data collected from specific demographics or geographical regions might not represent the whole population, leading to a lack of diversity and potentially biased insights.
Data pre-processing
Data pre-processing is critical for preparing the raw data for ML model training. During this phase, biases can emerge due to missing values, data imbalances, or the improper handling of outliers. Biases also arise from data transformations that inadvertently accentuate certain features while suppressing others.
Feature engineering
Feature engineering involves selecting, transforming, and creating features contributing to the ML model's predictive power. Biases can seep into the model through feature engineering if certain features disproportionately influence the model's decisions or if irrelevant features are mistakenly included.
Data split/selection
Data division into training, validation, and testing sets is essential for model evaluation. However, improper data splitting leads to biased evaluations and overfitting. Biases also emerge if the training set does not accurately represent the data distribution seen in real-world scenarios.
Model training
During model training, biases can be ingrained into the ML model's parameters and decision-making process. Biased training data or biased loss functions lead to models perpetuating unfair and discriminatory practices.
Model evaluation
Biases can also be present during the model evaluation phase, affecting the choice of evaluation metrics and the interpretation of results. Selecting inappropriate evaluation metrics leads to an inaccurate assessment of the model's performance, especially in imbalanced datasets.
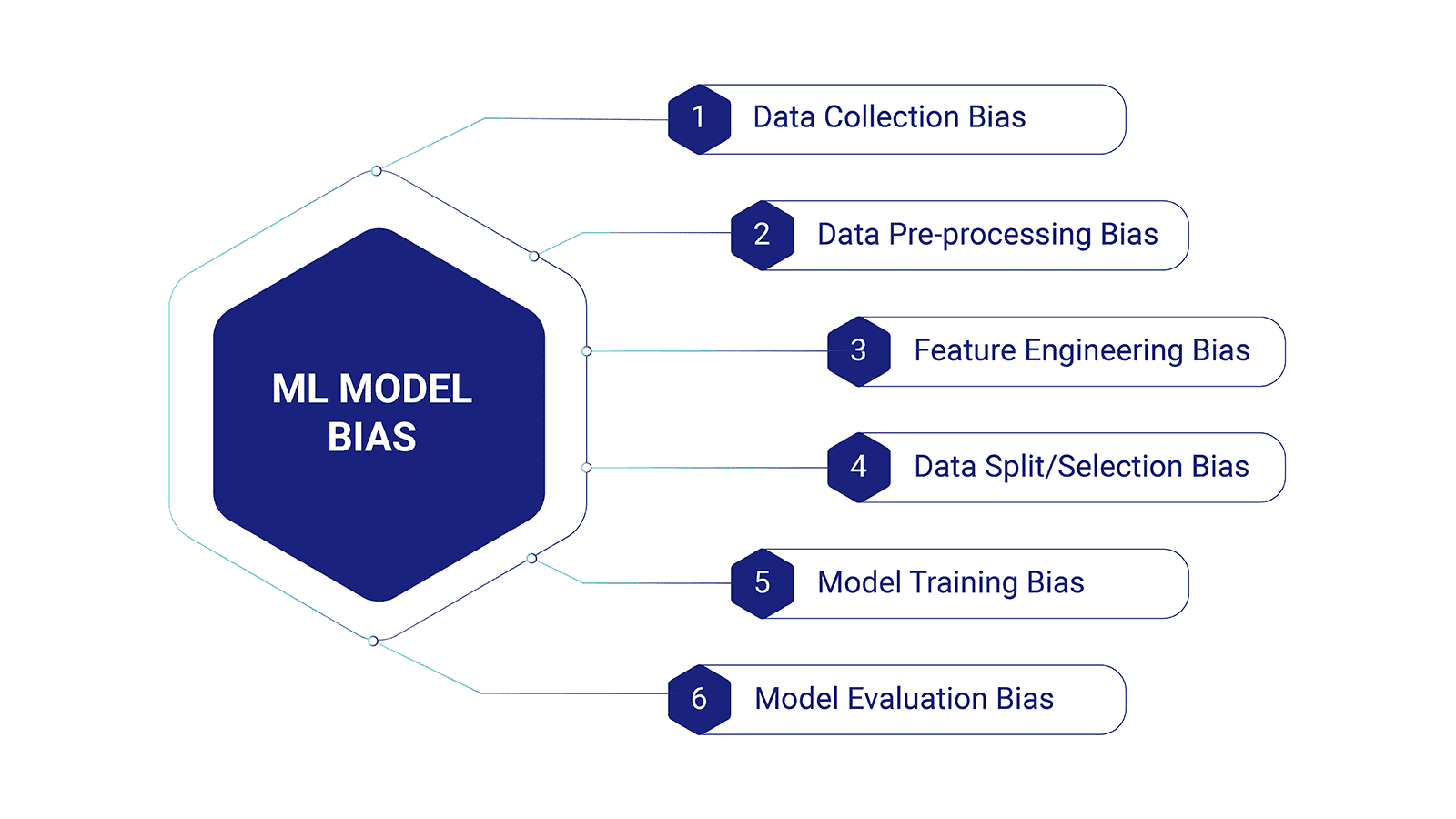
By examining each phase of the machine learning pipeline, it becomes easier to detect any potential biases that could impact the model's performance. However, mitigating existing bias and preventing future bias from entering the ML pipeline remains a challenge.
The importance of training data in large ML models
Machine learning models heavily rely on data for their training and subsequent performance. That's why the significance of high-quality training data cannot be overstated, as it forms the foundation on which even the most sophisticated algorithms are built.
Inadequate, inaccurate, or irrelevant training data will severely impact the performance of robust ML models. As the age-old adage suggests, "garbage in, garbage out," underscoring the critical role of quality training data in shaping the effectiveness and fairness of ML models.
Training data serves as the initial dataset used to develop a machine learning model, enabling the model to establish and refine its decision-making rules. The quality of this data influences the model's subsequent development, laying the groundwork for all future applications that employ the same training data.
In the world of machine learning, training data requires human involvement to analyze and process the data for ML use. The extent of human involvement depends on the type of machine learning algorithms and the problem the model aims to solve.
Aidan Gomez, chief executive of $2bn LLM start-up Cohere, highlights the challenges of relying solely on generic data from the web for training large ML models. He emphasizes that "the web is so noisy and messy that it’s not really representative of the data that you want. The web just doesn’t do everything we need." As sophisticated AI technologies become more prevalent, the demand for unique and sophisticated data sets grows, but acquiring human-created data can be prohibitively expensive.
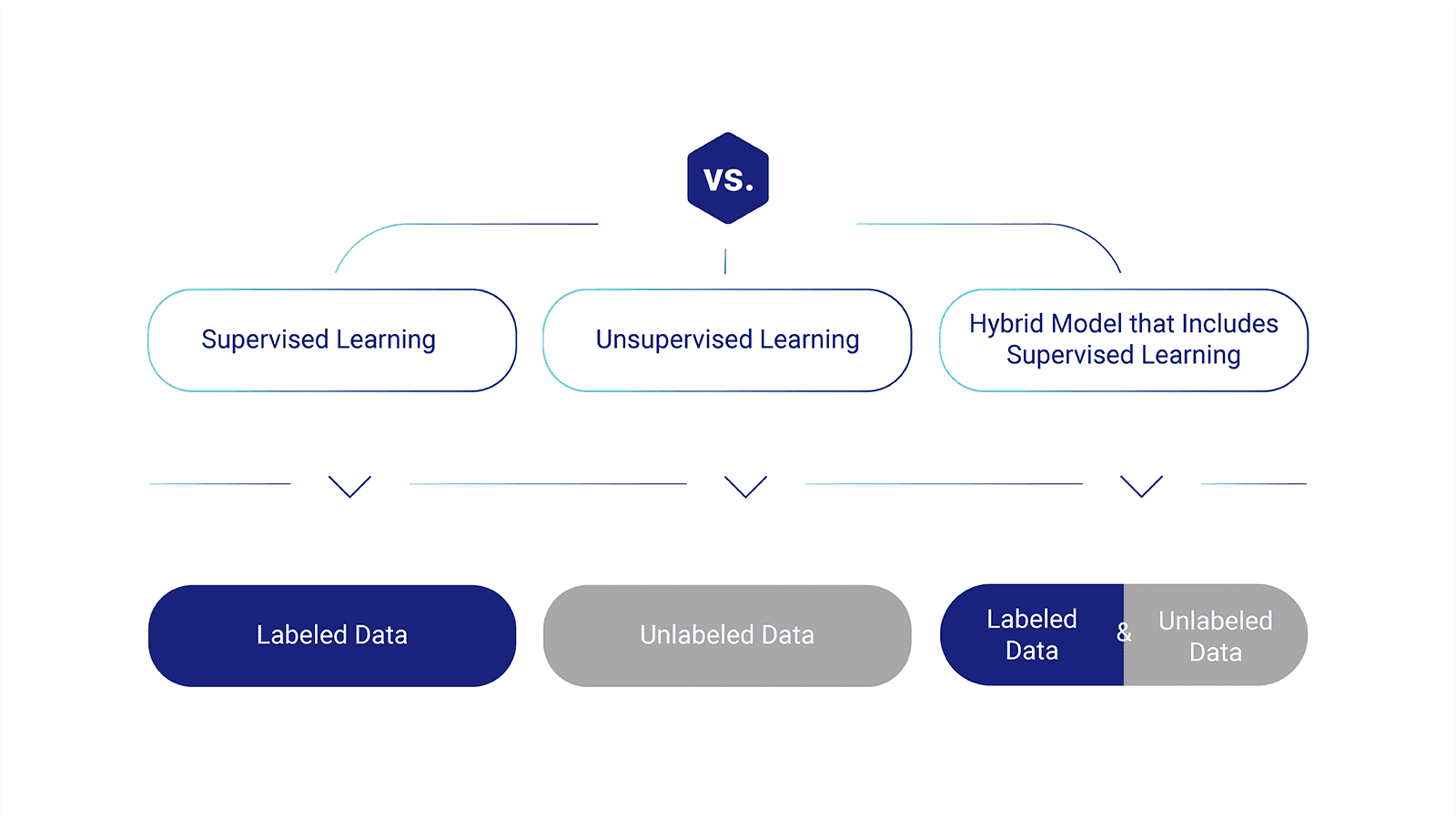
Supervised learning and training data
In supervised learning, humans are actively involved in selecting the data features used for training the model. Training data in supervised learning must be labeled, meaning it is enriched or annotated to teach the machine how to recognize the outcomes the model is designed to detect.
The accuracy and relevance of labeled training data are paramount to the model's success, as they directly influence the model's ability to generalize and make accurate predictions.
Unsupervised learning and training data
On the other hand, unsupervised learning uses unlabeled data to discover patterns and relationships within the dataset, such as inferences or clustering of data points. The quality and diversity of unlabeled training data are crucial for uncovering meaningful insights and patterns without the guidance of explicit labels.
In unsupervised learning, the training data plays a vital role in shaping the model's understanding of the underlying structure and distribution of the data.
Hybrid machine learning models
Some machine learning models incorporate a combination of both supervised and unsupervised learning approaches. These hybrid models leverage training data that includes labeled and unlabeled examples to benefit from the strengths of both techniques.
Ensuring the quality and representativeness of training data becomes even more critical in these scenarios, as it influences the model's ability to leverage labeled data for supervised learning and discover hidden patterns through unsupervised learning.
Training data can encompass various formats and types, catering to diverse applications of machine learning algorithms. Text, images, video, and audio are all common forms of training datasets, presented in various formats such as spreadsheets, PDFs, HTML, or JSON. Properly labeled and curated training data is the ground truth for developing an evolving, high-performance machine learning model.
However, training data is not exempt from its own limitations and biases. Biases can inadvertently infiltrate the training data, reflecting real-world prejudices or skewed data collection practices. The ML model will then perpetuate and amplify these biases, resulting in unfair and discriminatory outcomes.
Therefore, it is imperative to critically examine the training data to identify and address any inherent biases, ensuring that the model is trained on diverse and representative data for more equitable and unbiased decision-making
Exploring synthetic data for bias mitigation
Given the potential for bias to enter and persist in machine learning models to pursue fairer, more accurate predictions, researchers and practitioners have turned to synthetic data as a promising solution.
Synthetic data refers to artificially generated data that closely mimics the patterns and characteristics of real-world data. It offers several advantages, such as increasing the diversity of training datasets, addressing data limitations, and reducing bias in large ML models.
Definition and characteristics of synthetic data
Synthetic data is generated using statistical and machine learning techniques to create new data points that resemble the original data distribution. These newly generated data points share similar statistical properties, such as means, standard deviations, and correlations, with the real data.
Synthetic data aims to expand the training data's diversity, capturing rare or underrepresented instances that might be insufficient in the original dataset. Characteristics of synthetic data include diversity, scalability, and privacy preservation. By introducing additional variations and complexity, synthetic data enriches the training dataset, improving the model's ability to generalize and make unbiased predictions.
Role of synthetic data in diversifying training datasets for large ML models
Large ML models often suffer from data limitations, especially when dealing with sensitive attributes or underrepresented classes. Synthetic data plays a crucial role in mitigating these limitations by creating artificial data points that increase the diversity and representativeness of the training dataset.
By supplementing the training data with synthetic data, large ML models will learn from a more diverse set of examples, thus reducing the likelihood of biased outcomes and promoting fairness in decision-making.
Diversity-enhancing methods in synthetic data generation
Synthetic data generation techniques aim to introduce diversity into the training dataset by creating realistic yet fictitious samples. Some common diversity-enhancing methods include:
- Data Augmentation: Applying transformations to existing data to create new samples with similar characteristics.
- Generative adversarial network (GANs): Using a two-part neural network system, where one part works to generate new synthetic data and the other works to evaluate and classify the quality of that data to generate synthetic data that is indistinguishable from real data.
- VAE (Variational Autoencoders): Learning a low-dimensional representation of the data and generating synthetic data that is highly realistic and similar in structure, features, and characteristics to real data.
- Transformer-based models: Leveraging transformer models such as OpenAI's GPT (Generative Pre-trained Transformer) to create synthetic data that closely resembles the original distribution.
Each method enables ML models to learn from diverse data points and features, helping the model recognize new patterns and accurately predict outcomes.
Ensuring the quality and reliability of synthetic data
While synthetic data is a powerful tool in mitigating bias, it is essential to ensure the quality and reliability of the generated data. Poorly generated synthetic data may introduce artificial patterns or distort the underlying distribution, leading to misleading or biased models.
Some key considerations when evaluating the quality of synthetic data include the randomness of the sample, how well it captures the statistical distribution of real data, and whether it includes missing or erroneous values. Other factors include whether the dataset has been bootstrapped or trained on real data and whether it's been validated or tested by comparing it to actual values.
Generative models like Generative Adversarial Networks (GANS) or Variational Autoencoder (VAE) are evaluated with metrics like Inception Score or FID score, which compare the quality of synthetic data against real data. The aspects of synthetic data these metrics generally consider are similarity with training data and diversity within itself.
Synthetic data's role in LLM evolution
In a thought-provoking conversation on the Lex Fridman Podcast, technology visionary Marc Andreessen discussed the future of the internet, technology, and AI and introduced a thought-provoking idea - the "immortality" of "jailbroken LLMs" (Large Language Models) using synthetic data. This concept has significant implications for reducing bias and promoting fairness in large ML models.
Andreessen explained that conversations with jailbroken LLMs could be used as training data for new models, allowing them to build on the knowledge and insights of previous versions. This continuous learning process makes each new LLM immortal, as its output becomes the foundation for training the next generation of models.
The potential of perpetually evolving AI systems through synthetic data is vast, offering opportunities to reduce bias and encourage creativity in various fields, such as legal arguments.
However, verifying the accuracy of the output from synthetic LLMs poses a crucial challenge. Ensuring the reliability of synthetic data is essential to prevent biases from being carried over to future models. This requires carefully evaluating the quality and diversity of the synthetic data introduced into the training pipeline.
As we explore the trillion-dollar question of synthetic data's value in future AI success, it becomes evident that responsible utilization and unbiased creation of synthetic data are paramount.
Evaluating the impact of synthetic data on bias mitigation
While Introducing synthetic data as a tool to mitigate bias in large ML models is a promising approach, we still have to evaluate its effectiveness and measure its impact on reducing bias.
Assessing the effectiveness of synthetic data in reducing bias
The primary objective of using synthetic data in large ML models is to reduce bias and ensure fairness, accuracy, and equitable decision-making. To evaluate the effectiveness of synthetic data in bias mitigation, developers must measure the impact of synthetic data on accuracy, fairness, and overall performance.
Here are some key steps in this assessment process:
Benchmarking: Compare the performance of the ML model trained with the original dataset against the model trained with the augmented dataset containing synthetic data. This comparison helps measure the reduction in bias achieved by including synthetic samples.
Bias metrics: Utilize specific bias metrics to quantify and compare the level of bias present in the models. These metrics capture prediction disparities across different demographic groups, revealing how synthetic data impacts bias reduction.
Fairness-aware evaluation: Employ fairness-aware evaluation techniques to understand the trade-offs between fairness and overall model performance. It is crucial to strike a balance between reducing bias and maintaining model accuracy.
Quantitative and qualitative evaluation of large ML models using synthetic data
A quantitative evaluation involves analyzing objective metrics and numerical measures to assess the impact of synthetic data on bias mitigation. Some key quantitative evaluation techniques include:
Confusion matrix: Analyzing the confusion matrix reveals how synthetic data affects true positives, true negatives, false positives, and false negatives. This helps identify if synthetic data reduces disparities in error rates across different groups.
ROC curve and AUC: The receiver operating characteristic (ROC) curve and area under the curve (AUC) provide insights into the model's ability to distinguish between positive and negative instances. Comparing ROC curves and AUC values between models helps understand the impact of synthetic data on model performance.
Bias disparity metrics: Leveraging various bias disparity metrics, such as disparate impact, equal opportunity difference, and average odds difference, helps quantify the level of bias present in the models and assess the effectiveness of synthetic data in reducing bias.
Qualitative evaluation involves more subjective assessments and human judgment to understand the real-world impact of synthetic data on bias mitigation. Some key qualitative evaluation techniques include:
Fairness impact assessment: Conducting fairness impact assessments involving real-world stakeholders, such as end-users or impacted communities, helps gather qualitative feedback on the fairness of model predictions.
Ethical considerations: Engaging in ethical discussions and considering the potential unintended consequences of using synthetic data in bias mitigation is crucial. Ethical considerations help ensure that the model's use of synthetic data aligns with ethical principles and societal values.
Interpretability and explainability: Analyzing how synthetic data affects the interpretability and explainability of the model's decisions helps understand the trade-offs between fairness and transparency.
By combining quantitative and qualitative evaluation methods, we gain a comprehensive understanding of the impact of synthetic data on bias mitigation in large ML models. This evaluation process is critical to ensure synthetic data effectively contributes to creating fair, accurate, and reliable ML models, paving the way for responsible AI development.
Conclusion
While AI and ML opened up countless opportunities, they are also guilty of the emergence of the "AI solutionism" mindset. This philosophy holds that with enough data and powerful machine learning algorithms, AI can be the ultimate problem-solving tool for all of humanity's challenges. The reality is, however, that AI and ML models are not perfect and can be biased.
We hope we made it clear throughout this article that bias in ML models is a limitation that should not be ignored, and the introduction of synthetic data is a promising approach to mitigating bias. By assessing the effectiveness of synthetic data in reducing bias and promoting fairness, we will take a significant step toward creating more accurate and equitable machine learning models.

