Synthetic financial data: a solution to the problem of limited data availability
.webp?width=1600&height=900&name=Blog-Synthetic-Financial-Data%20(1).webp)
In finance, data is king. The more data you have, the more insights you can gain and the better decisions you can make. But what if you don't have enough data, or the data you have is biased, incomplete, or outdated? That's where synthetic financial data comes as a game-changer.
Synthetic data is artificial data generated by computer algorithms to mimic the patterns and characteristics of real-world data. Think of it as a "digital twin" of your data but with more flexibility and diversity. By using synthetic data, you can supplement or replace your real-world data and get more accurate and comprehensive results. And that's not just a theory.
Synthetic data has already proven valuable in various finance domains, from asset management to insurance, banking, and fintech. In this blog post, we'll dive deeper into the world of synthetic financial data and show you how it can help you solve the problem of limited data availability.
What is synthetic financial data?
At its core, synthetic data is a computer-generated representation of real-world financial data. But unlike real-world data, which is collected from various sources such as stock exchanges, regulatory filings, or surveys, synthetic financial data is created from scratch based on predefined rules or statistical models. This gives it some distinct advantages over traditional data sources, such as flexibility, scalability, and privacy.
Synthetic financial data aims to provide additional data points similar to real-world data, allowing for more comprehensive analysis and modeling. It supplements existing data sets or creates new ones, enabling a more detailed look at financial trends and patterns.
Beyond data privacy: the benefits of synthetic financial data
When you think of synthetic financial data, what is the first thing that comes to mind? Do you think of it mainly as a fix for data privacy issues, allowing you to share data without compromising sensitive information?
While data privacy is paramount, synthetic financial data is much more than a privacy shield. Generating synthetic data for financial institutions opens up a world of possibilities and improvements to your machine learning (ML) processes and model development. And many of those have nothing to do with privacy or security.
According to Gartner, 80% of heritage financial services firms will go out of business, become commoditized or exist only formally but not compete effectively by 2030. Banks that remain in business will need a strategy to stay ahead of the curve, and generating, using, and sharing synthetic financial data is the key to achieving this goal.
Here are some of the main benefits synthetic financial data will bring to your organization:
Improved data quality and diversity
Synthetic data is generated to represent a wide range of scenarios and events, allowing you to create more diverse and representative datasets than those available from traditional sources. This diversity improves the accuracy of your models and enables better predictions and risk assessments.
Enhanced scalability
Traditional financial data is often limited in scope and volume, making it difficult to scale up models and predictions. With synthetic data, however, you’re able to generate as much data as you need to support your ML algorithms, allowing you to expand your operations without constraints.
Improved risk management
Synthetic data simulates different risk scenarios, allowing you to test and refine your risk management strategies before implementing them in the real world. By running simulations on synthetic data, you will better understand and anticipate risk and minimize losses while reducing the time and resources needed to develop your models.
Enhanced collaboration and knowledge sharing
Due to its privacy-preserving capabilities, synthetic financial data is easily shared and distributed within and between organizations, enabling better collaboration between departments and teams. By collaborating on synthetic data, you will build on your organization's collective knowledge and expertise, improving the quality of your models and predictions.
Improved regulatory compliance
Synthetic data helps financial organizations comply with strict data privacy and security regulations, such as GDPR, CCPA, and the Swiss nFADP. It allows organizations to train their models without using real-world data, which may contain sensitive or personally identifiable information. This means you can test and validate your models while remaining compliant with regulations and avoiding potential legal liabilities.
Better innovation and experimentation
Synthetic financial data is your secret weapon for innovation and experimentation. It allows you to prototype new financial products, services, and business models without risking real-world assets. This means you experiment more freely and get creative with your ideas, knowing you can test and validate them in a safe and time-effective way.
From stress testing to fraud detection: how synthetic financial data is changing finance
While digital transformation has become a priority for banks, on that route, they are confronted with a series of challenges, such as privacy regulations, workforce training, new processes, and risks associated with using real-world data. Perhaps the biggest bottleneck is the legacy banking systems' inability to accommodate the needs of modern financial institutions, which require greater flexibility and scalability.
So how can synthetic financial data help? For starters, it offers a range of use cases across various finance domains, including asset management, insurance, banking, and fintech. The Financial Conduct Authority (FCA) has created a collaborative exploration of synthetic data, including a list of use cases for synthetic financial data, such as fraud/financial crime, AI/LM development, credit/lending risk, and more. You can view the FCA's presentation for more information, while we cover a few practical use cases in more detail:

Anti-money laundering
Money laundering refers to the process of disguising the origin and destination of illegal money and channeling it into the regular financial system. By generating large sets of synthetic transactions, organizations train and test their anti-money laundering (AML) models to detect suspicious activity more accurately. Potential accounts, transactions, payments, and withdrawals or purchases are better identified and flagged for further investigation through the use of synthetic data. Patterns of criminal activity can still be seen in the synthetic data, allowing organizations to hone their AML models and stay ahead of new criminal tactics.
Fraud detection and risk management
Fraud detection is another area where synthetic data is proving useful. By generating synthetic data that mimics real-world fraud patterns, institutions will improve their fraud detection models and reduce the number of false positives. Similarly, with synthetic data, banks simulate different risk scenarios to fine-tune their risk management strategies and ensure they are operating at optimal levels.
Data bias reduction
One of the challenges of using real-world data is that it can be biased, leading to models that perpetuate this bias. Even though synthetic data is not immune to it either, it can definitely help reduce the risk of data being used to perpetuate prejudices. By creating datasets more representative of the entire population, including underrepresented groups, institutions will ensure their models are not based on faulty data.
Credit scoring and loan origination
Credit scoring is a critical function in the financial industry, and synthetic data plays a significant role in improving credit risk models. It generates digital twins of customers and simulates their credit scores, enabling lenders to make more accurate loan origination decisions.
By stimulating a broad range of scenarios and borrower characteristics and behaviors, institutions will better understand the creditworthiness of their clients, leading to more accurate credit decisions and better risk management.
Portfolio optimization
Portfolio optimization is the process of selecting the optimal mix of investments to achieve a specific financial objective. With synthetic data, institutions generate vast amounts of data on different investment scenarios and evaluate the performance of various portfolios. This helps them identify the most profitable and efficient portfolios, leading to better returns for their clients.
Stress testing and scenario analysis
One of the primary applications of synthetic financial data is stress testing and scenario analysis. This involves creating hypothetical scenarios and simulating how a portfolio or financial instrument would perform under those conditions. With synthetic data, institutions generate a diverse range of scenarios that are difficult or impossible to obtain from real-world data. This allows them to test the robustness of their models and prepare for a range of potential market conditions.
The recent partnership between Basinghall Analytics and Syntheticus, announced in March 2023, is a great example of how synthetic financial data is used for stress testing and scenario-based financial planning. The joint proposition of Basinghall's proprietary risk tools with Syntheticus' privacy-preserving synthetic data capabilities enables financial institutions to extract maximum insights from sensitive data without compromising compliance with data protection and privacy regulations. This partnership provides a game-changing solution for financial institutions to build new models, validate and monitor them, and perform stress testing and scenario-based financial planning.
Deep dive into a recent use case: synthesizing a finance relational database
At Syntheticus, we love tackling challenging projects that push the boundaries of what's possible with data and take pride in our ability to solve complex data challenges for our clients. Recently, we had the opportunity to partner with a client in the finance industry who needed a solution for their large and complex financial data.
They were struggling to manage >8 million rows of data spread across a dozen tables connected through referential integrity.
*Given the client’s privacy, we’re not disclosing the actual underlying data but only a public dataset for the sake of showcasing the results. See below for the entity relationship diagram.

To tackle the challenge, we leveraged our expertise in data modeling and database design to optimize the tables for performance and scalability while maintaining referential integrity. Using the Syntheticus Hub, we seamlessly connected to the client's database. The platform's out-of-the-box integrations support various services such as AWS, Google, Azure, Snowflake, Databricks, and integration with enterprise databases such as Oracle, MySQL, MongoDB, PostgreSQL, MariaDB, and many others.

After only a few minutes of reviewing the client’s underlying data model, the platform generated a synthetic version of the entire database with a dozen tables, each with a specific set of fields to accommodate the client's requirements, and over 8 million records. We take quality seriously, and so the platform conducted a thorough Quality Assurance (QA) report to ensure that the database met the highest standards. The QA report highlighted the main metrics, including data accuracy, completeness, privacy, and consistency, for each single table as well as for the database.
Here are some of the main metrics found within the QA report:
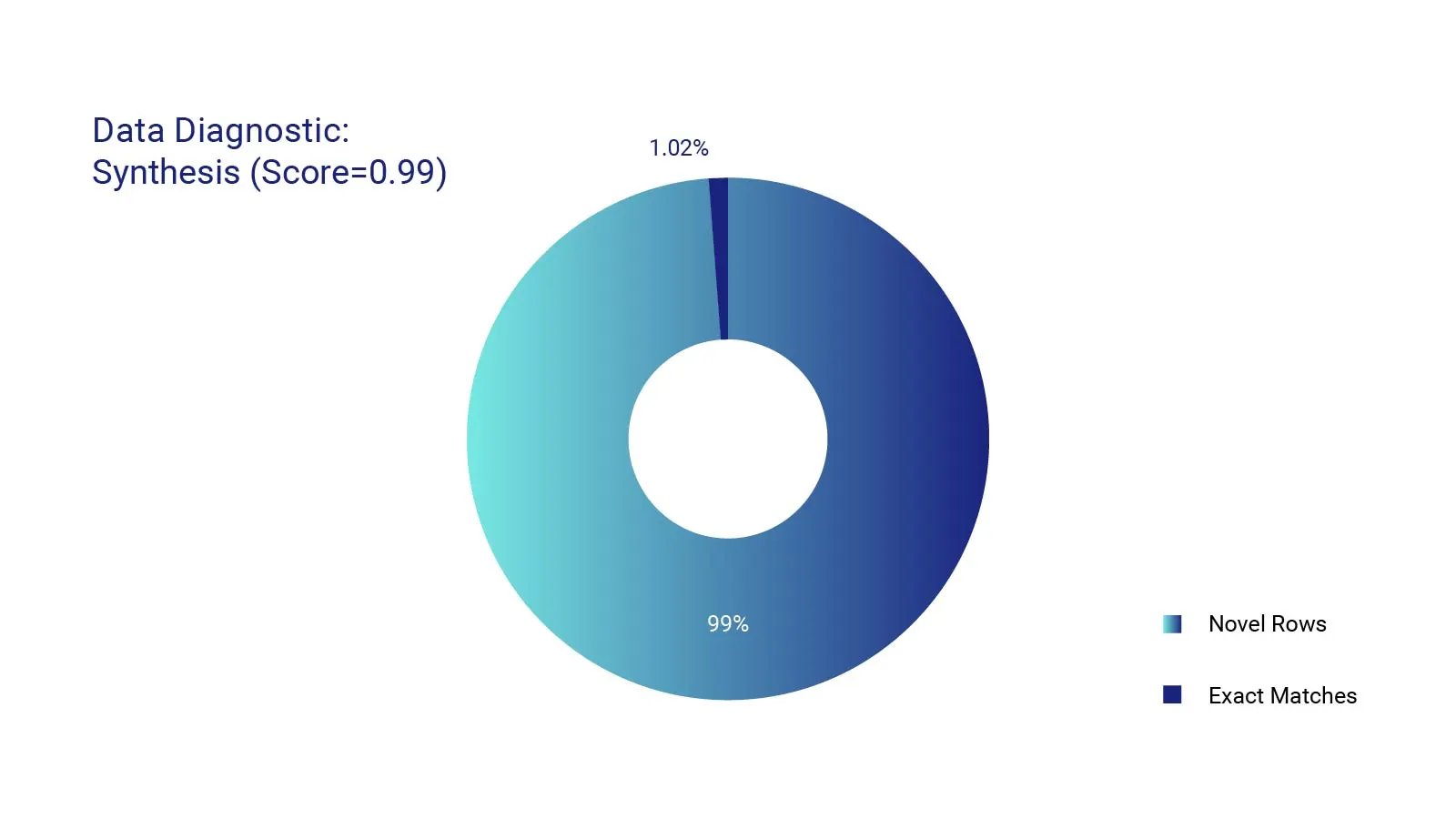
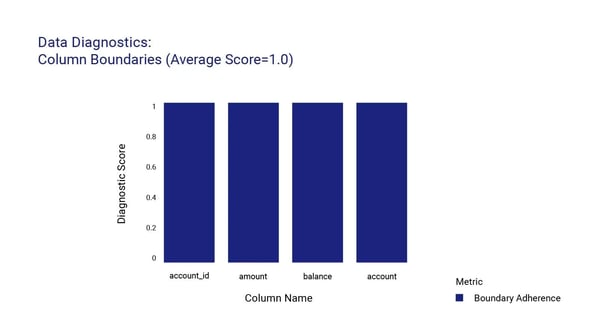
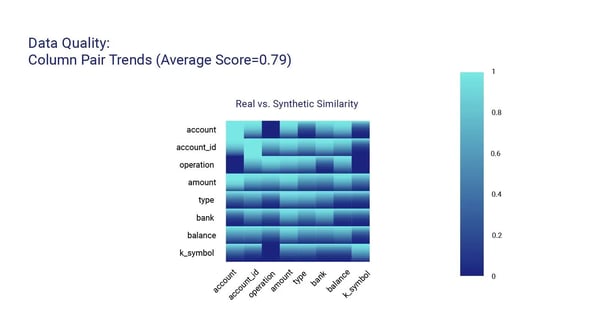
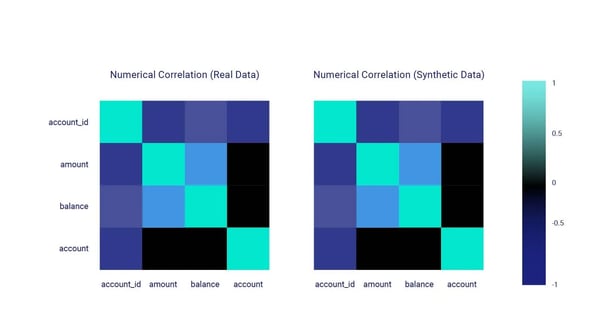
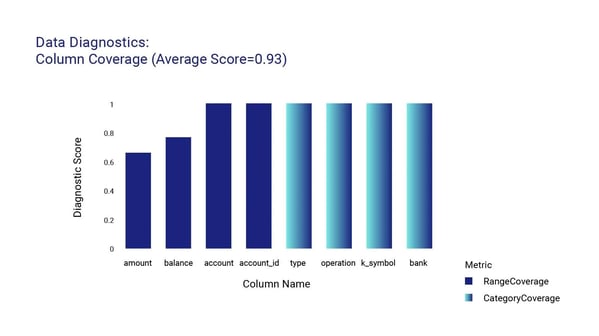
After delivering the optimized and quality-assured relational database to our client, we provided them with a set of recommendations to further improve the database's functionality and usability. Our team at Syntheticus takes pride in delivering solutions that meet and exceed our client's expectations and we're thrilled to have provided our client with a sophisticated database solution that simplifies their data management and supports their business goals.
Best practices and considerations for using synthetic financial data
If you've decided to leverage synthetic financial data for your institution, there are a few things to keep in mind to ensure you're using it effectively and responsibly.
First, it's crucial to select appropriate models that are relevant to your use case. Different models have different strengths and weaknesses, and you should choose one that fits your specific needs. For example, if you're looking to generate data for credit risk analysis, you might choose a model that accurately simulates default probabilities and other credit risk metrics.
But selecting the suitable model is just the first step. You need to validate the quality and reliability of the synthetic data you generate. This means running tests to ensure your data is accurate, unbiased, and representative of real-world financial data. Only then can you have confidence in the insights you extract from it.
Of course, ethical and legal considerations also come into play when working with synthetic financial data. Data privacy is a big one, as synthetic data is sometimes derived from real-world data containing personally identifiable information (PII). Intellectual property is another concern, as some synthetic data generation techniques may involve proprietary algorithms or models.
Another important consideration when working with synthetic financial data is ensuring compliance with regulatory requirements. Depending on your industry and location, specific regulations or guidelines may dictate how to generate and use synthetic data. Make sure to do your research and consult with legal experts to ensure you're following all applicable regulations and guidelines.
Finally, the lack of clear standards on privacy can create uncertainty around how to best protect sensitive information in synthetic datasets. Syntheticus recognizes this challenge and actively participates in the IEEE Standards Association, which has set up an IC Expert Group to set a standard for structured privacy-preserving synthetic data.
Transparency, explainability, and accountability are essential principles to keep in mind when using synthetic financial data. You need to be able to explain how the data was generated, what assumptions were made, and what the limitations of the data are. This is important both for internal decision-making and for external stakeholders who may be relying on it.
The future of data-driven financial services
The financial services industry is undergoing a significant transformation driven by advances in technology and the growing importance of data. The future of banking will be shaped by the ability to use data-driven decision-making and successful digital transformation. One of the biggest challenges in this context is handling bank-specific and personal data and its processing by artificial intelligence.
Synthetic financial data is likely to become even more important for institutions in the years to come. The increased availability of synthetic data will allow institutions to leverage AI and machine learning to make more informed decisions while complying with data privacy and regulatory requirements. As new technologies like blockchain and distributed ledgers become widespread, the potential applications for synthetic data will only grow. From risk management and compliance to fraud prevention and customer segmentation, synthetic financial data will become an essential tool for banks and other financial institutions.
However, this future has challenges, including data privacy concerns, cybersecurity risks, and regulatory compliance. As the industry continues to evolve and new use cases emerge, financial services companies must balance the opportunities presented by data-driven insights with the potential risks to ensure long-term success. Synthetic financial data will be essential to this equation and will help bridge the gap between traditional services and digital banking. To learn more about how synthetic data can address IP and privacy issues of artificial intelligence, check out our podcast episode with Giulio Coraggio, location head of the Italian Intellectual Property & Technology department of the global law firm DLA Piper.
As synthetic financial data solutions continue to evolve, the possibilities are endless. With careful planning, ethical considerations, and a clear understanding of its potential applications, financial institutions capitalize on this opportunity and create a data-driven future in banking.

